Простой команды из 10 разработчиков всего на 4 часа стоит 100 000 рублей — и это только прямые издержки. В масштабах крупного проекта десять дней простоя способны увеличить бюджет на 12-15%, а для компании с оборотом 100 млн рублей потеря одного рабочего дня означает ущерб в 274 000 рублей. При этом реальные потери могут в разы превышать прямые убытки из-за репутационных рисков, штрафов и потери клиентов. О том, во сколько обходятся простои российским ИТ-компаниям, «Компьютерра» рассказывает в новом материале.

Анатомия простоя: что это такое и почему неизбежно
Простой в ИТ-компании — это любая остановка рабочих процессов, когда команда не может выполнять свои функции. В отличие от производственных предприятий, где простой означает остановку конвейера, в ИТ последствия могут быть более критичными и долгосрочными.
Аутсорсинговые ИТ-компании прописывают время простоя в соглашении об уровне предоставляемых услуг — SLA. Например, если uptime (время бесперебойной работы) равно 99,9%, — это означает, что простой в месяц может составить не более 43,5 минут в месяц.
«Простои могут быть разных типов. Мы разделяем запланированный перерыв в функционировании и нарушение деятельности из-за проблемы, связанной с воздействием извне — чаще всего речь идет о злоумышленниках», — объясняет управляющий RTM Group, эксперт в области кибербезопасности и права в ИТ Евгений Царев.
Полностью избавиться от простоев будет дорого и сложно. По мнению Царева, для этого требуется дублирование серверов в независимых друг от друга контурах. Именно поэтому простои случаются почти у каждой компании.
«Потери в том или ином виде случаются у любой организации не менее 1-2 раз в год. Особенно если она ведет операционную деятельность в автоматизированном виде».
Евгений Царев, управляющий RTM Group, эксперт в области кибербезопасности и права в ИТ
Математика убытков: считаем реальную стоимость
Понимание масштаба проблемы начинается с точного расчета финансовых потерь. Самую простую формулу предлагает Алексей Оносов, основатель компании «Юнисофт»: «Берем годовые продажи, делим на 525 600 минут в году, умножаем на время простоя. Добавляем зарплаты простаивающих сотрудников и затраты на восстановление». Таким образом, получается внушающая сумма.

«Если речь идет о команде из 10 разработчиков с медианной ставкой 2500 рублей в час, то простой в 4 часа уже обходится в 100 000 рублей — и это только прямые издержки», — поясняет Юрий Гуржий, CMO компании Evrone.
Переводя эти цифры на полный рабочий день, получается внушительная картина убытков. Так, при среднем рабочем дне в 8 часов в случае простоя получается:
- команда из 10 разработчиков: 200 000 руб./день;
- команда из 20 специалистов: 400 000 руб./день;
- команда из 50 человек: 1 000 000 руб./день.
Особенно драматична ситуация в банковском ИТ-аутсорсе. Директор по развитию в СНГ Selecty Эдуард Долгалев раскрывает структуру затрат: по его словам, в проектах по ИТ-аутсорсу для банков не менее 50% общих затрат составляет фонд оплаты труда. При простое команда не приносит ценности, считает эксперт.
«Простой 10+ рабочих дней на типовом проекте из 8–10 человек способен создать перерасход бюджета до 12–15%, не считая репутационных издержек», — подсчитал Долгалев.
Скрытые потери
Прямые затраты на зарплаты и восстановление — лишь верхушка айсберга. За ними скрываются менее очевидные, но не менее существенные виды ущерба.
Упущенная прибыль
«Вторая составляющая потерь — это упущенная прибыль, которая может достигать 15–25% от плановой выручки проекта», — объясняет Долгалев. Эти потери возникают при:
- срыве сроков выхода продуктов
- нарушении требований регуляторов
- потере SLA на стороне клиентского сервиса
Каждый из этих факторов может привести к каскадному эффекту, когда один сбой влечет за собой цепочку негативных последствий для всего проекта.
Операционные издержки
Еще одной категорией скрытых издержек считаются операционные расходы, которые связаны с устранением последствий сбоя.
«К прямым потерям от остановки ключевых бизнес-процессов неизбежно добавляются операционные издержки: компенсация труда простаивающего персонала, оплата сверхурочной работы ИТ-команд, экстренные закупки запасных частей», — детализирует дополнительные расходы руководитель Центра экспертизы по комплексному сервису К2Тех Наталия Сляднева.
Репутационные риски
Наиболее сложно поддающимся оценке, но крайне важным фактором остается репутационный ущерб. «Многие компании отмечают потерю доверия клиентов после серьезных сбоев — это репутационные риски, которые в деньгах не посчитаешь», — подчеркивает Оносов.
Главные причины простоев в 2025 году
Понимание механизмов возникновения простоев — первый шаг к их предотвращению. Эксперты выделяют несколько ключевых факторов, провоцирующих сбои в работе ИТ-систем.
Коммуникационные сбои
Парадоксально, но в эпоху цифровых технологий человеческий фактор остается главной причиной технических проблем. «Простои чаще всего происходят из-за проблем в коммуникации заказчика и подрядчика. Отсутствует backlog, есть внутренние задержки у подрядчика», — выделяет главную причину Долгалев.
Технические факторы
Наряду с коммуникационными проблемами, существует целый комплекс технических причин сбоев. «Главные причины: износ оборудования, проблемы с электричеством, кибератаки и банальные ошибки персонала», — перечисляет Оносов.
Гуржий конкретизирует технические причины для разработки:
- неработающие CI/CD пайплайны
- падение инфраструктуры
- блокировки доступа (VPN, лицензии)
- задержки от внешних подрядчиков
Эти технические сбои часто взаимосвязаны и могут провоцировать друг друга, создавая эффект домино в ИТ-инфраструктуре.
Системные проблемы отрасли
К ним Сляднева относит накопление устаревших систем в инфраструктуре, сокращение ИТ-бюджетов и затянувшееся импортозамещение. «С уходом зарубежных вендоров оборудование остается без прямой поддержки, фактически работая в режиме “обратного отсчета”», — считает эксперт.
Ситуацию усугубляют и ИБ-угрозы, способные полностью вывести инфраструктуру из строя. Поэтому, по мнению Слядневой, важно инвестировать не только в системное плановое обслуживание, но и в грамотное проектирование ИТ-инфраструктуры еще на старте.
Как часто происходит простои
«Мелкие инциденты случаются почти еженедельно, крупные — несколько раз в год», — делится статистикой Гуржий из Evrone. При этом «лайтовые» простои длительностью час-два из-за отключения электричества случаются чаще, но «редко разрушительно воздействуют на системы», отмечает Царев. Более серьезные сбои происходят реже, но их последствия могут быть катастрофическими.
«У нас в “Юнисофт” был случай — сервер “лег” на два часа в пятницу вечером. Казалось бы, мелочь, но с нашим уровнем цифровизации производство простаивало. Итог — сотни тысяч рублей прямых потерь плюс нервы всей команды на выходных».
Алексей Оносов, основатель компании «Юнисофт»
Стратегии минимизации потерь
Осознание масштаба проблемы естественным образом приводит к поиску решений. Эксперты предлагают комплексный подход к минимизации рисков простоев.
Гибридные модели работы
Одним из эффективных инструментов управления рисками становится гибкость в организации рабочих процессов. «Основная команда работает по T&M-контракту с плавающей загрузкой. Это позволяет оперативно масштабировать или сужать состав без штрафов», — объясняет компания Selecty.
Организация также использует модель «часового кредита» — перераспределяют ресурс на смежный проект клиента без дополнительных затрат.
Превентивные технологии
По мнению экспертов, профилактическое обслуживание снижает незапланированные сбои. «Мониторинг в реальном времени через датчики и системы интернета вещей предупреждает о перегреве, перегрузках, износе за недели до поломки», — приводит пример Оносов.
Планы восстановления
Чтобы простой не был неожиданностью, к нему лучше заранее подготовиться. «Чтобы защититься превентивно, необходимо составить и хотя бы раз в год тестировать план восстановления, чтобы каждый понимал, кто за что отвечает и что нужно делать», — советует Царев. Тогда и сотрудники будут действовать с меньшей долей паники, и проблема, вызвавшая простой, может решиться быстрее.
Рекомендации по типам компаний
Универсального рецепта от простоев не существует — эффективная стратегия должна учитывать специфику бизнеса и ресурсные возможности компании.
Для продуктовых компаний:
- Внедрить мониторинг и алертинг на всех уровнях
- Предусмотреть резервные каналы и инфраструктуру
- Регулярно проводить стресс-тесты
Продуктовые компании несут максимальные репутационные риски при сбоях, поскольку напрямую взаимодействуют с конечными пользователями, что требует особого внимания к отказоустойчивости системы.
Для аутсорсинговых компаний:
- Использовать гибридные T&M-контракты
- Подготовить специалистов на замену заранее
- Внедрить модель «часового кредита»
Аутсорсинговые компании работают в условиях жестких контрактных обязательств, где простои напрямую влияют на выполнение SLA и могут привести к штрафным санкциям.
Для крупных корпораций:
- Привлечь сервис-провайдеров для комплексного обслуживания
- Разделить критичные сервисы и повысить их отказоустойчивость
- Выработать надежный подход к бэкапированию данных
Хотя крупные корпорации располагают большими ресурсами для создания комплексных систем защиты, у них более сложная и разветвленная ИТ-инфраструктура, требующая системного подхода.
«Инвестиции в отказоустойчивость и процессы реагирования окупаются буквально за одну предотвращенную аварию», — резюмирует Гуржий.
При стоимости одного крупного сбоя от нескольких сотен тысяч до миллионов рублей, вложения в превентивные меры выглядят более чем оправданными.
Выводы
Анализ российского ИТ-рынка показывает, что простои стали частью digital-реальности, требующей системного подхода к управлению рисками.
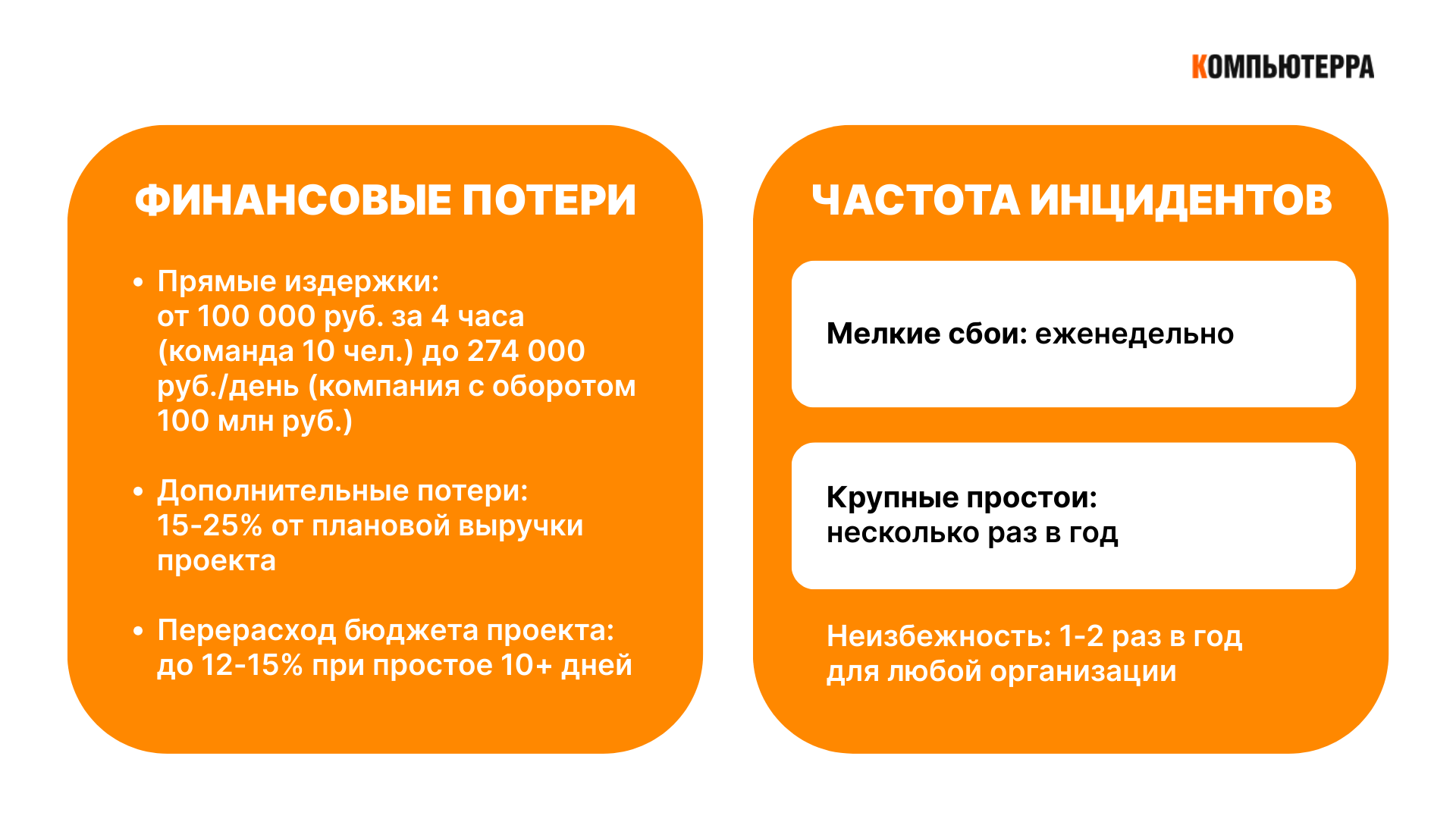
Эти цифры финансовых потерь показывают, что стоимость простоев сопоставима с годовыми ИТ-бюджетами многих компаний. Это делает инвестиции в превентивные меры экономически обоснованными.
В свою очередь, регулярность инцидентов подтверждает, что простои — это не исключительное событие, а постоянный операционный риск, который требует системного управления. При выборе стратегии защиты от простоев важно учитывать специфику и возможности компании.
Стоит инвестировать в превентивные меры, если:
- компания работает с критически важными системами (здравоохранение, промышленность, связь, энергетика и тд.);
- есть опытная ИТ-команда для внедрения мониторинга;
- бюджет позволяет вложения в отказоустойчивость;
- важна репутация и клиентский сервис.
Стоит обратиться к внешним поставщикам услуг по защите, если:
- нужны быстрые результаты при ограниченном бюджете;
- отсутствует экспертиза для создания комплексных систем;
- простои не влияют существенно на выручку.
Современные ИТ-руководители должны рассматривать инвестиции в отказоустойчивость не как техническую задачу, а как критически важный элемент бизнес-стратегии. При правильном подходе профилактика простоев окупается уже после предотвращения первого крупного сбоя, а долгосрочная экономия может достигать миллионов рублей в год.