
Открытая библиотека программного обеспечения RAPIDS™ от NVIDIA, позволяя применить графические платы для ускорения решения задач обработки больших данных и машинного обучения, может послужить входным билетом в мир самых перспективных ИТ-приложений.

Фейерверк высокоэффективных и высокоприбыльных приложений, который обрушивают на нас деловые и технологические новостные ленты, в немалой степени связан с анализом больших данных и машинным обучением. Эти технологии используются везде – от научных исследований и больших финансов до управления транспортно-складской логистикой и отлова незаконных мигрантов с помощью уличных видеокамер. Емкость данного рынка очень солидная – ее на 2018 г. оценивают в $42 млрд., обещая двукратный рост к 2024 г., и подъем на уровень $103 млрд. к году 2027. Причём в обоснованность такой динамики вполне верится.
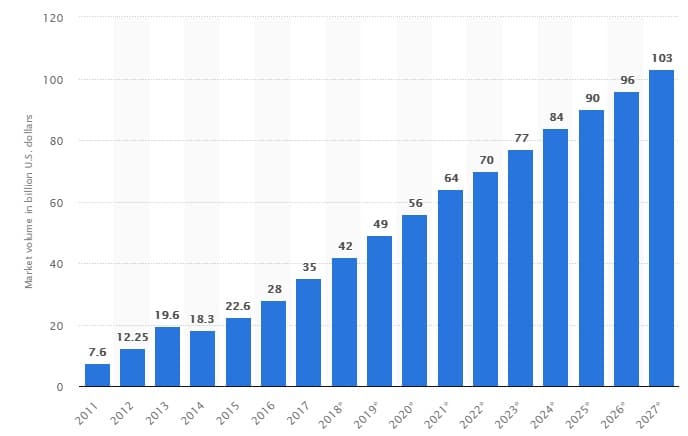
Для того, чтобы яснее представить величину этих денежных сумм, скажем, что в 2011-2015 гг. США продали различных вооружений на сумму $46,4 млрд., а Россия – на $35,4 млрд. То есть –нынешний объем рынка больших данных лежит между объемами экспорта крупнейших поставщиков вооружений (аккумулировавших научную и инженерную мысль десятилетий) за пятилетку. А объем бигдэйты, прогнозируемый на 2027 г. – это ж как те оборонные контракты с Саудовской Аравией, за которые президент Трамп готов простить расчленёнку оппозиционера в стамбульском консульстве…
То есть – речь в одной лишь подотрасли идет о деньгах, сравнимых с глобальным экспортом оборонки. В перспективе – о деньгах, за которые глава крупнейшей страны готов забыть о моральных нормах… И это – лишь большие данные. А есть еще машинное обучение. Которое росло в деньгах по 34% (так называемый CAGR – Compound Annual Growth Rate) с 2013 по 2017 г.г., достигнув $12 млрд., и ожидает к 2021 г. повышения до $57,6 млрд. Тоже довольно привлекательный кусок пирога…
Но как же выйти на этот рынок, как приобщиться к эти фантастическим объемам? Возможно ли это в отечественных условиях? Ведь еще математик Евклид разъяснял царю Птолемею, что в геометрии царских путей нет… И это верно по-прежнему. Без знаний, без напряженного труда дороги в хайтек нет. А вот возможность обойтись относительно скромными начальными затратами при разработках и внедрении технологий больших данных и машинного обучения сейчас появляется. И даёт эти возможности библиотека с открытым кодом.
Зовется она – RAPIDS™. Из значка товарной марки мы видим, что библиотека не является плодом труда группы бескорыстных энтузиастов, а представляет собой вполне профессиональный продукт корпорации NVIDIA . Интерес которой вполне ясен и понятен – библиотека позволяет использовать графические ускорители этой корпорации для решения задач обработки больших данных и машинного обучения ИИ. «Разложить» на нижнем уровне их алгоритмы под специализированную архитектуру GPU.
На создание библиотеки RAPIDS™ у команды разработчиков NVIDIA, тесно взаимодействовавшей с ведущими специалистами открытых архитектур, ушло два года. «Под» библиотекой RAPIDS™ лежит широко известная CUDA – более десяти лет назад бывшая аббревиатурой от Compute Unified Device Architecture, а сейчас ставшая просто словом, вроде лейки, ксерокса, диктофона… Обозначающим платформу параллельных вычислений. CUDA позволяет реализовывать на диалектах языков C, C++, FORTRAN алгоритмы параллельных вычислений, которые выполняются на графических и тензорных процессорах от NVIDIA. Оформленные в виде функций эти алгоритмы можно вызвать как из языков высокого уровня, типа Python, так и из специализированных пакетов, вроде общеизвестного MATLAB.

Сегодня CUDA широко используется во всем мире для решения научных, инженерных, деловых задач самого различного профиля. Ну а новая библиотека RAPIDS™ – это еще более высокоуровневый инструмент, с помощью которых можно набрать реализацию алгоритмов обработки больших данных и машинного обучения. Тестовые задачи, в ходе которых «бустерный» алгоритм машинного обучения XGBoost, прогонялся системе NVIDIA DGX-2™, показали пятидесятикратный прирост производительности по сравнению с системами на базе центральных процессоров.
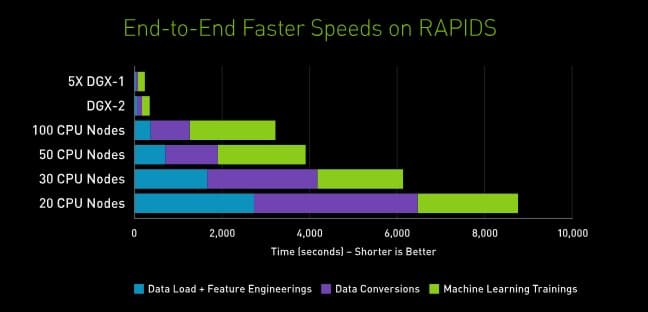
То есть – в зависимости от размерности массива данных, на которых происходит обучение, характеристическое время этого процесса сжимается от часов к минутам, от суток к часам, от года к неделе. Ну а это – в одних случаях в десятки раз сокращает инвестиции на разработку и эксплуатацию системы. В других – при ограниченности ресурсов – позволяет резко удешевить «входной билет» и в большие данные и в машинное обучение. Делает их доступными начинающему ИТ-предпринимателю с идеей; молодому ученому с ограниченным бюджетом, а то и школьнику, зарабатывающему на конкурсе грант на учёбу в приличном университете.
Библиотеки RAPIDS™ интегрированы не только с программными продуктами от NVIDIA, но и с известными и широко распространенными продуктами обработки данных, такими как Apache Arrow, pandas и scikit-learn. NVIDIA интегрируют RAPIDS в Apache Spark – наиболее распространенную программную платформу для анализа неструктурированных и слабоструктурированных данных, входящую в «бигдатовскую» экосистему Hadoop. RAPIDS резко ускоряет работу Apache Spark, а повсеместность «Искры» должна способствовать распространению новой библиотеки.
Таким образом бурно развивающиеся отрасли ИТ-бизнеса получают новый инструмент, который для достаточно многих вполне может оказаться входным билетом на поезд высокотехнологического прогресса и личного успеха…