

Гиперконвергентные системы (HyperConvergedSystems – HCI) на сегодняшний день занимают прочные позиции на рынке инфраструктурных решений и показывают стабильную тенденцию к росту, несмотря на свою молодость. Доверие к ним растет, параллельно возрастает спрос на HCI-решения, а предложения не заставляют себя долго ждать, поступая от все новых игроков в этой сфере ИТ-решений. Но что же сделало их такими популярными по сравнению с «классической» моделью, разделяющей уровни вычислительных мощностей, системы хранения и вопросы коммутации? Все достаточно просто.
Интеграция и сопровождение подобных систем требует гораздо меньших накладных расходов, снижает риск эксплуатационных ошибок, а также появляется несравнимая гибкость в масштабировании данных систем, делая их привлекательными для развертываний любого масштаба.
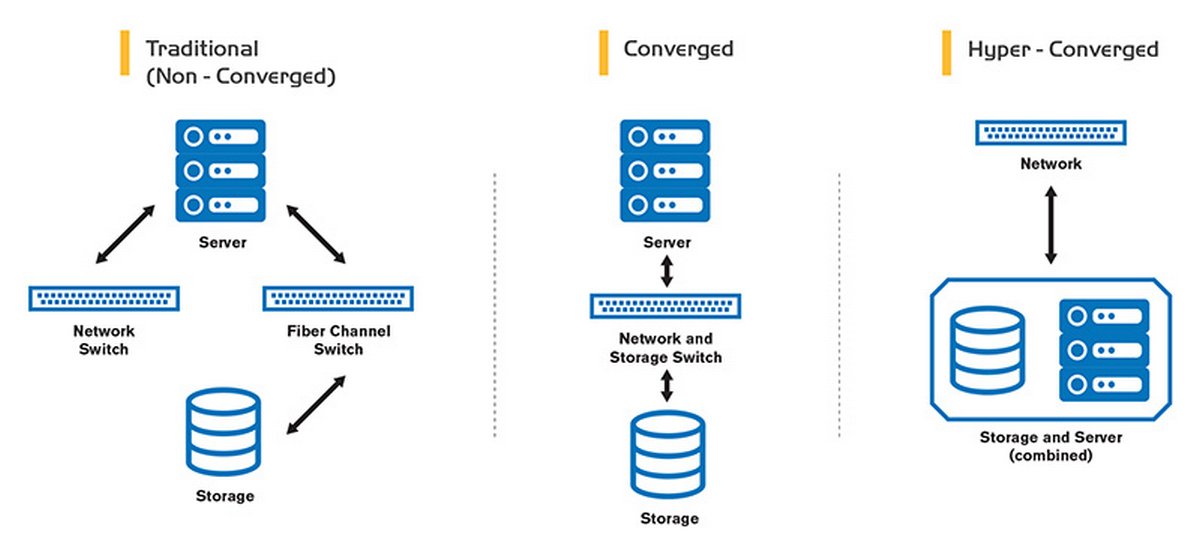
Несмотря на явные преимущества, HCI на сегодняшний день пока еще неспособны вытеснить классические решения, поэтому легко интегрируются с ними, позволяя сделать переход более плавным, избегая крупных затрат на этапе внедрения и не закапывая уже вложенные инвестиции в текущую инфраструктуру. Модель HCI, с одной стороны, сильно упрощена архитектурно, что дает возможность оперативнее реагировать на требования бизнеса. С другой стороны, данные системы зачастую выигрывают в производительности у других решений и лучше масштабируются, что повышает конкурентоспособность бизнеса без избыточных капиталовложений.
Можно возразить, что все эти вопросы легко закрываются и на системах, построенных по принципам трехуровневой модели инфраструктуры (сервер, СХД, сеть). Все это так, но, посчитав затраты на эксплуатацию, когда зачастую в разделенных схемах существует необходимость оплачивать специалистов на каждом из уровней этой системы, можно прийти к выводу, что классическая схема имеет крайне много нюансов, делающих ее менее гибкой и более требовательной к экспертизе, интеграционным и эксплуатационным затратам, не говоря уже о временных.
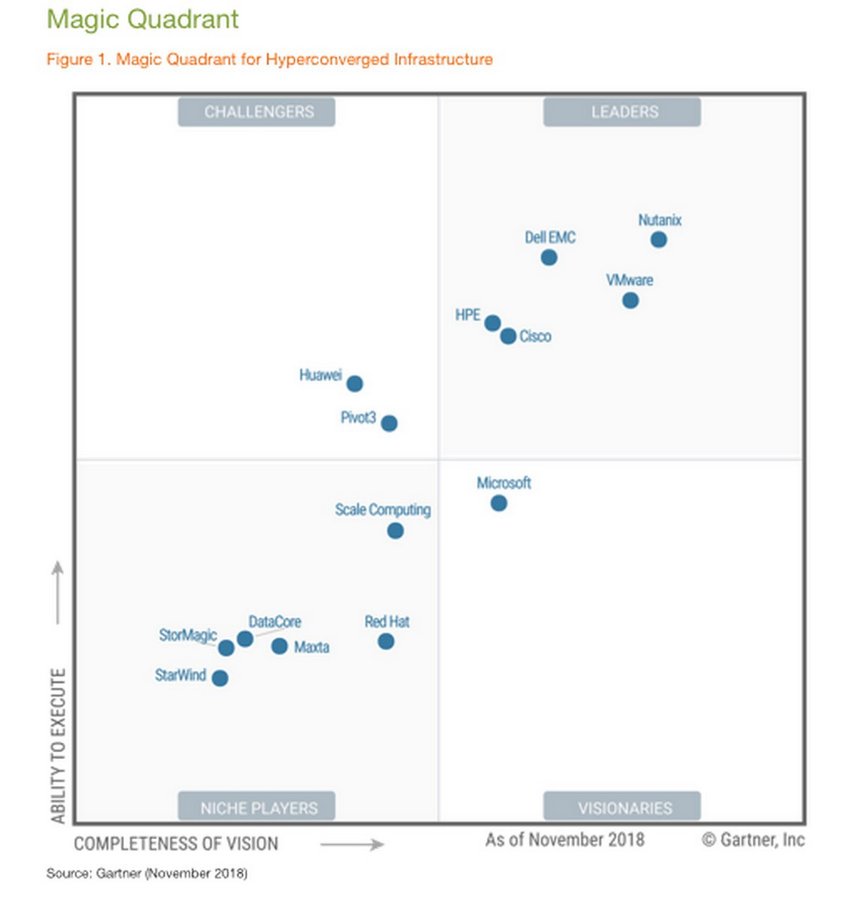
Ярким представителем HCI от компании Cisco, продвинувшим ее вверх по квадрату Гартнера на рынке гиперконвергентных систем наряду с Nutanix, VMWare, Dell EMC и HPE, стало представленное в 2016 году решение HyperFlex.
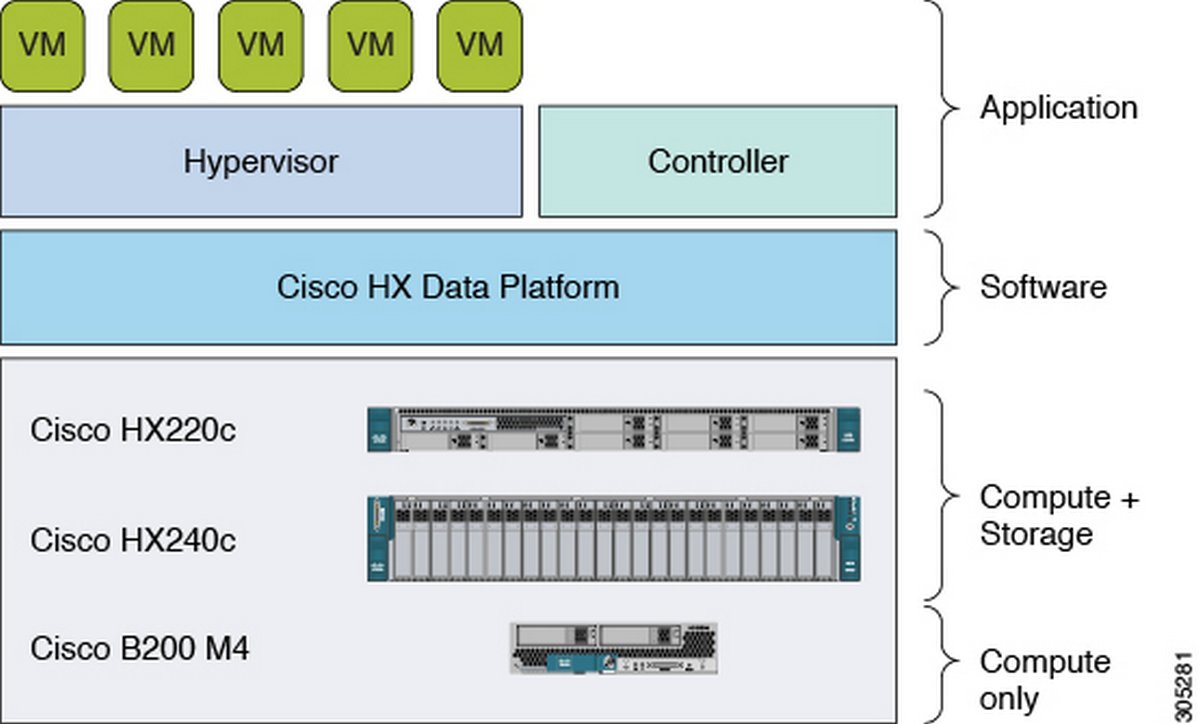
Решение разработано на базе платформы Cisco Unified Computing System (Cisco UCS), совмещая в себе со стороны вычислительной части как стоечные ноды HX2xx, так и бездисковую реализацию блейд-систем (об этом чуть ниже).
Система хранения получила название HX Data Platform и создана по принципу SDS (Software Defined Storage). Она позволяет собрать в единый пул хранения все носители информации в пределах кластера. Естественно, поддерживается All-Flash и в ближайшем будущем – NVMe-реализация. В качестве сети используется обязательный компонент вычислительной фабрики Cisco UCS – Fabric Interconnect с колоссальной скоростью работы и минимальными показателями задержек, что является крайне важными параметрами в гиперконвергентных решениях.
Первоначальное конфигурирование и дальнейшая настройка серверов (firmware, raid, bios и прочие) осуществляется с помощью так называемых сервисных профилей, когда, имея в распоряжении преднастроенные шаблоны, нам становится безразлично – один сервер добавляется в кластер или 100.
Для управления платформой хранения данных (HX Data Platform) также доступны плагины для консолей управления MSSC и VMWare.
В результате мы получили готовое к работе из коробки, управляемое из единого места, надежное, мощное и гибкое решение, масштабирование которого сводится к простому добавлению необходимых блоков. Это могут быть бездисковые блоки вычисления или, наоборот, блоки, расширяющие возможности системы хранения данных, совмещенные с вычислительной частью. HyperFlex, кроме гипервизора от компании VMWare, поддерживает Hyper-V и контейнерную виртуализацию.
Давайте поговорим о каждой из составляющих чуть подробней.
Система хранения данных
Подсистема хранения в решениях HyperFlex вышла максимально гибкой. Все носители на базе вычислительных нод объединяются в единый кластер, а при необходимости система расширяется добавлением HX2xx нод, имеющих в своем распоряжении корзину вместимостью 10 или 24 дисков, в зависимости от модели сервера. Узлы с классическими HDD называются гибридными, они имеют маркировку HX220c и HX240c.
Поддерживаются классические, гибридные, ALL-Flash и ALL-NVMe ноды, что не только дает гибкость в выборе решений, исходя из требований к производительности, но и корректирует их исходя из бюджета. ALL-FLASH-серверы именуются HXAF220c и HXAF240c. При добавлении новой ноды хранилище расширится без потери работоспособности всей системы. Взаимодействие происходит по 10 или 40 Gbit/s Ethernet. Управление HX Data Platform осуществляется из единой точки. На каждой ноде обязателен SSD или NVMe под кэширование данных.
Важный нюанс: в системе нет такого понятия, как локальное хранение. Вычислительные ноды могут интегрироваться в систему без единого носителя информации, но за счет сетевой составляющей HyperFlex не возникает проблем с доступом к необходимым данным и сетевой стек является тут не узким горлышком, а надежным связующим звеном.
Отказоустойчивость системы хранения обеспечивается за счет репликации данных между узлами. Присутствуют неотъемлемые для современной системы хранения данных функции моментальных снимков, клонирования и дедупликации, что позволяет уменьшить стоимость хранения до 80%.
Важным нюансом использования HX Data Platform является отсутствие необходимости отказываться от уже купленных систем хранения – их можно интегрировать в HyperFleх.
Вычислительная часть

Computing (вычислительная часть) реализована в HyperFlex крайне интересно. Как и в системе хранения, главную роль исполняют серверы HX220 и HX240. За основу в них взяты стоечные серверы C220 и C240. Обязательным атрибутом ноды HX2xx является наличие m.2-диска под установку гипервизора и отдельного диска под логирование. Вроде все просто: добавляем еще одну ноду в кластер, получаем бОльшую производительность. Но дьявол, как всегда, кроется в деталях. Поскольку уровень хранения в HyperFlex «глобален» в рамках решения, нет необходимости с каждым сервером переплачивать за носители. Можно просто добавить так называемую Compute Node, которая не будет нести на себе носители информации, а добавит только заявленные показатели производительности в кластер. Это позволяет очень гибко расширять кластер.
Еще одним нюансом является возможность использовать в роли Compute Node стоечные и блейд-серверы UCS C и B серии. В компаниях, где уже использовалось серверное оборудование фирмы Cisco, HyperFlex может быть расширен уже имеющимися серверами. Но нужно иметь в виду, что расширение кластера подобным образом возможно только в вычислительном плане. То есть добавить носители информации в общий пул HX Data Platform не получится, эта роль полностью ложится на серверы HX и HXAF. Также необходимо упомянуть, что количество бездисковых Compute Node должно быть меньше или равно Storage-образующих узлов.
Сетевая составляющая

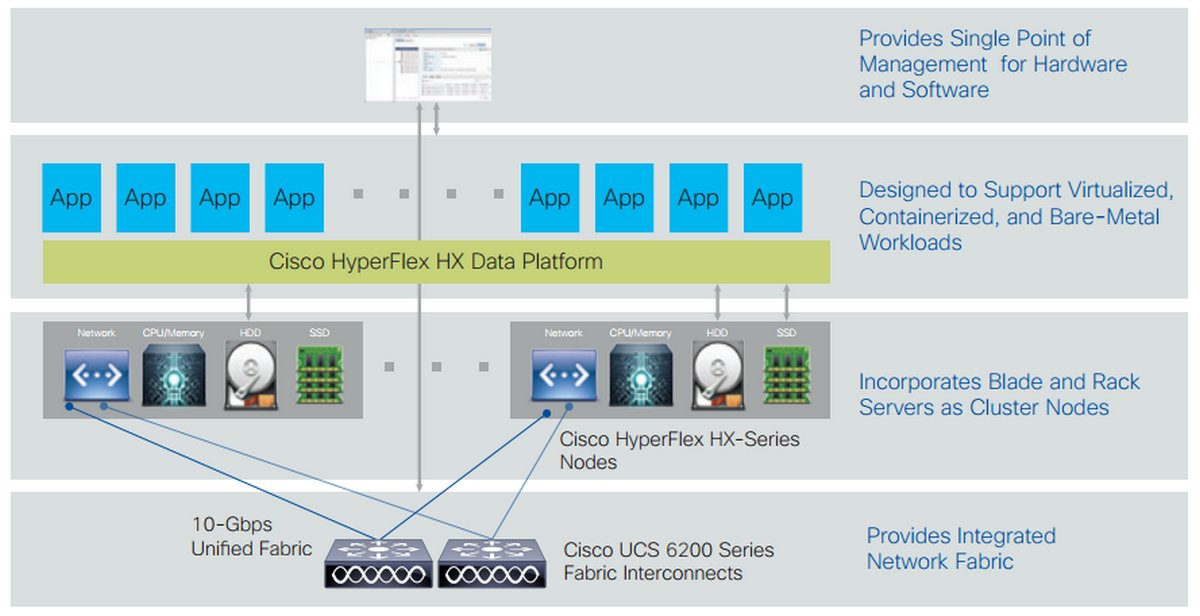
Компания Cisco не была бы собой, если бы наряду с другими преимуществами платформы ярче всего не выглядела бы именно сетевая часть системы и конвергентная система Fabric Interconnect, которая является в HyperFlex фундаментом для построения всего комплекса. Fabric Interconnect служит унифицированной технологией и стирает грани между сетью передачи данных и сетью хранения, максимально упрощая взаимодействие и масштабирование всех узлов системы. А дублирование Fabric Interconnect обеспечивает необходимый уровень отказоустойчивости.
На практике это выглядит еще проще, чем в теории. Каждый узел несет на себе так называемый vic (Virtual Interface Card) интерфейс, который соединяется с общей для решения парой коммутаторов Fabric Interconnect. Последний обеспечивает инкапсуляцию внутри фабрики в единый стандарт, давая возможность взаимодействовать с любым типом трафика, а конечные потребители (Виртуальные машины) получают виртуальные интерфейсы того протокола, который им необходим. То есть, подключив физически сервер из vic в Fabric Interconnect, мы создаем виртуальные интерфейсы (LAN, SAN, Management и пр.) на уровне абстракции ниже, чем уровень гипервизора, и с помощью технологии directpath i/o отдаем виртуальным машинам напрямую. Это дает нам отличную возможность минимизировать влияние на все машины гипервизора, а также оптимально работать с огромными потоками данных, таких как видеоконтент, без потери качества, так как снижается влияние гипервизора в обмене и это существенно снижает показатели задержек и нагрузку на вычислительную часть всей системы. Нетрудно представить, какую гибкость дает подобный конвергентный подход.
Управление
А вот теперь – самое интересное для тех, кто не был знаком с настройкой серверов UCS ранее. Первичная настройка сервера осуществляется при помощи так называемых сервисных профилей (service profile), которые конфигурируются и хранятся на – внезапно! – Fabric Interconnect. Данные профили представляют собой, по сути, xml с настройками bios settings, bios firmware, RAID, NIC Settings and firmware и прочее. Выглядит это следующим образом: вы конфигурируете профиль для сервера, добавляете сервер в кластер и просто нацеливаете этот профиль на новый сервер. Все! Через некоторое время сервер готов к эксплуатации. А теперь представьте, что вам необходимо настроить 20 дополнительных серверов в ЦОД или обновить у группы серверов версию firmware. Для этого вам потребуется затратить усилий ровно столько же, сколько этого потребовало бы конфигурирование одного сервера.
Для удобства управления HyperFlex Data Platform реализован плагин для vSphere Web Client и аналогичное решение для продукта от Microsoft, позволяющее унифицировать управление всего программно-аппаратного комплекса. Больше нет необходимости разграничивать зоны ответственности специалистам разного профиля. Системой может управлять один администратор, и требования к общей компетенции снижаются.
Выводы
У Cisco получилось крайне интересное решение, полностью отражающее принципы построения HCI-систем. Решение гибкое, очень хорошо и просто масштабируемое, которое способно существенно сократить затраты на внедрение и поддержку.
Время разворачивания данной системы крайне мало, а легкость масштабирования и управления делает решение крайне любопытным для эксплуатации как в ЦОД, так и в Enterprise-инфраструктурах различного масштаба. Компания Cisco ярко вышла на рынок HCI-систем, довольно быстро закрепившись в лидирующем квадрате Гартнера в этом сегменте рынка.
Каков портрет потребителя и use cases продукта, мы обсудим в следующей части статьи. Также поговорим о производительности и обсудим реальные примеры внедрения и использования платформы.