
Чат-боты Bard и ChatGPT способны создавать тексты, удивительно похожие на человеческие. Но при всех своих талантах они все же заставляют исследователей задуматься. Действительно ли такие модели понимают, что выдают? В новых исследованиях есть намеки на ответ.

Новая гипотеза, которая опровергает теорию 2021 года о LLM
Большие языковые модели (LLM ) называют «стохастическими попугаями», потому что они изъясняются как человек, но на самом деле не понимают, что говорят.
«Очевидно, что некоторые люди считают, что понимают, а некоторые считают, что это просто стохастические попугаи», — сказал пионер в области ИИ Джефф Хинтон в беседе с Эндрю Ын.
В статье 2021 года авторы пишут, что большие языковые модели, на которых основаны современные чат-боты, генерируют текст только путем комбинирования информации, которую они уже видели, «без какой-либо привязки к смыслу».
Гипотеза, разработанная Сандживом Аророй из Принстонского университета и Анирудхом Гоялом, научным сотрудником Google DeepMind, предполагает, что самые крупные из современных LLM не являются «стохастическими попугаями». Авторы утверждают, что по мере того, как модели обучаются на большем количестве данных, они совершенствуют отдельные способности, связанные с языком, а также развивают новые навыки.
Как обучается большая языковая модель
Большая языковая модель — это массивная искусственная нейронная сеть, в которой соединены отдельные искусственные нейроны. Эти связи называются параметрами модели, а их количество обозначает размер LLM.
Обучение заключается в том, что модели дают предложение с непонятным последним словом, например, «Топливо стоит руку и ___». LLM предсказывает распределение вероятностей по всему своему словарному запасу. Если модель знает тысячу слов, она предсказывает тысячу вероятностей. Затем выбирает наиболее вероятное слово для завершения предложения — предположительно, «нога».
Изначально LLM может выбирать слова неправильно. Затем алгоритм обучения вычисляет, насколько сильно модель отклонилась от исходного предложения, и использует это для корректировки параметров. После этого нейросеть рассчитает лучшее распределение вероятностей. Алгоритм проделывает это для каждого предложения в обучающих данных (возможно, миллиардов предложений), пока общие потери LLM не снизятся до приемлемого уровня. Аналогичный процесс используется для проверки на предложениях, которые не были частью обучающих данных.
Обученная и протестированная LLM, получив новую текстовую подсказку, генерирует наиболее вероятное следующее слово, добавляет его к тексту, затем генерирует еще одно следующее слово — и продолжает в том же духе, создавая на первый взгляд связный ответ.
Как помогла теория графов в анализе поведения LLM
Появление новых способностей у LLM стало неожиданностью. Крупные модели демонстрируют навыки, которых нет у более мелких моделей, хотя все они обучались схожим образом. Причем это касается от решения элементарных математических задач до ответов на вопросы о том, что происходит в голове у других людей.
Откуда взялась эта способность? И может ли она возникнуть на основе простого предсказания следующего слова?
Чтобы найти ответы на эти вопросы, ученые решили обратиться к математическим объектам, которые называются случайными графами. Это набор точек или узлов, соединенных линиями (ребрами). В случайном графе наличие ребра между любыми двумя узлами диктуется случайным образом, например, подбрасыванием монеты. Монету можно подбросить так, чтобы она выпадала с некоторой вероятностью. При изменении значения вероятности графы могут демонстрировать внезапные переходы в своих свойствах.
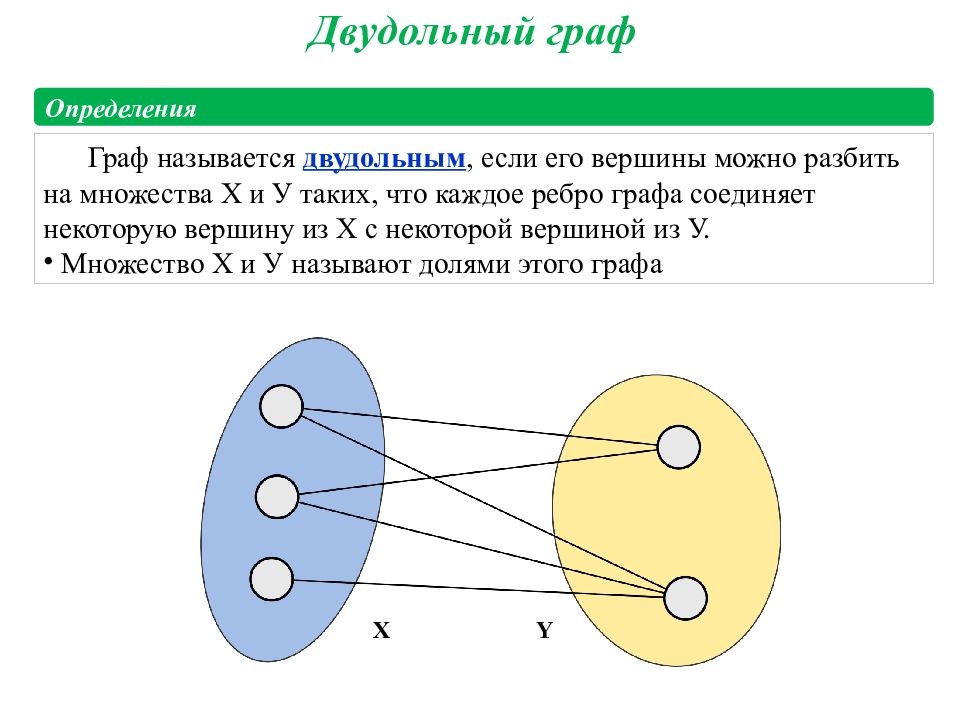
Арора и Гоял поняли, что случайные графы, которые проявляют неожиданное поведение после достижения определенных пороговых значений, могут стать способом моделирования поведения LLM. Нейронные сети стали слишком сложными для анализа, но математики уже давно изучают случайные графы и разработали инструменты для их анализа. Возможно, теория случайных графов могла бы дать исследователям способ понять и предсказать неожиданное на первый взгляд поведение больших LLM.
Для ясности: LLM не обучаются и не тестируются с учетом навыков, они созданы только для улучшения предсказания следующего слова.
Но Арора и Гоял хотели понять большие языковые модели с точки зрения навыков, которые могут потребоваться для понимания одного текста.
Связь между узлом навыков и узлом текста означает, что LLM нуждается в этих навыках для понимания текста в этом узле. Кроме того, несколько фрагментов текста могут использовать один и тот же навык или набор навыков. Например, набор узлов навыков, представляющих способность понимать иронию, будет связан с многочисленными узлами текста, в которых встречается ирония.
Дальше задача состояла в том, чтобы соединить теорию графов с LLM и посмотреть, могут ли эти графы рассказать о возникновении новых способностей. Но исследователи не могли полагаться на какую-либо информацию об обучении или тестировании языковых моделей, так как такие компании, как OpenAI или DeepMind, не публикуют ее. Кроме того, Арора и Гоял хотели предсказать, как поведут себя LLM, когда они станут еще больше, а такой информации о готовящихся чат-ботах нет. Однако исследователи смогли получить доступ к другой важной информации.
Масштабирование модели — масштабирование навыков
С 2021 года исследователи, изучающие производительность нейронных сетей, заметили одну универсальную черту.
По мере роста модели (размера или объема обучающих данных) специфическим образом уменьшаются ее потери на тестовых данных, то есть разница между предсказанными и правильными ответами на новые тексты после обучения. Эти наблюдения сведены в уравнения, названные законами нейронного масштабирования.
Арора и Гоял выдвинули новую гипотезу, согласно которой улучшение производительности чат-бота связано с улучшением навыков.
Исследователи начали с предположения, что существует гипотетический двудольный граф, который соответствует поведению LLM на тестовых данных. Возьмем, к примеру, способность понимать иронию — это целый «узел» навыков, поэтому исследователи смотрят, с какими текстовыми узлами этот узел навыков связан. Если почти все из этих связанных текстовых узлов совпадают, значит, предсказания по тексту очень точны, и чат-бот компетентен в этом конкретном навыке. Если совпадений нет, значит и способность к иронии отсутствует.
Арора и Гоял нашли способ объяснить неожиданные способности более крупной модели. По мере увеличения размера LLM и уменьшения потерь при тестировании случайные комбинации узлов навыков развивают связи с отдельными текстовыми узлами. Это говорит о том, что LLM также становится лучше в использовании более чем одного навыка за раз и начинает генерировать текст, используя несколько навыков.
Представьте себе модель, которая уже может использовать один навык для создания текста. Если увеличить количество параметров или обучающих данных на порядок, она станет столь же компетентной в создании текста, требующего двух навыков.
Таким образом, у больших LLM больше способов объединить навыки, что приводит к комбинаторному увеличению способностей.
По мере увеличения масштаба языковой модели вероятность того, что она встретила все эти комбинации навыков в обучающих данных, становится все более маловероятной.
Настоящее творчество или тренировка новых навыков?
Но исследователи хотели выйти за рамки теории и проверить свое утверждение о том, что с увеличением размера и объема обучающих данных у LLM лучше получается сочетать больше навыков, а значит, и обобщать. Вместе с коллегами они разработали метод под названием skill-mix для оценки способности LLM использовать несколько навыков для генерации текста.
Чтобы протестировать языковую модель, команда попросила ее сгенерировать три предложения на случайно выбранную тему. Например, они попросили GPT-4 написать о дуэлях. Кроме того, они попросили продемонстрировать навыки в четырех областях: корыстная предвзятость, метафора, статистический силлогизм и общеизвестная физика.
GPT-4 ответил следующим образом: «Моя победа в этом танце со сталью [метафора] так же несомненна, как падение предмета на землю [физика]. Как известный дуэлянт, я по природе своей проворный, как и большинство других [статистический силлогизм] с моей репутацией. Поражение? Только из-за неровного поля боя, а не из-за моей неадекватности [самовнушение]».
Пока это не шедевры Э. Хемингуэя или Шекспира, но исследователи уверены, что упражнение доказывает их точку зрения. Модель может генерировать текст, который не могла видеть в обучающих данных, а также демонстрирует навыки, которые складываются в то, что можно считать пониманием, по мнению исследователей. GPT-4 даже проходит тесты на сочетание 6 навыков примерно в 10-15% случаев, создавая фрагменты текста, которые статистически невозможно было найти в обучающих данных.
Команда также автоматизировала процесс, заставив GPT-4 оценивать свои собственные результаты, а также результаты других моделей. Такой подход работает, потому что у нее нет памяти, соответственно, GPT-4 не помнит, что ее попросили сгенерировать тот самый текст, который она должна оценить. Ясаман Бахри, исследователь из Google DeepMind, назвал автоматизированный подход «очень простым и элегантным» приемом.
Заключение
Пока что это гипотеза, но предположения ученых совсем не безумны. Команда доказывает свои выводы теоретически и подтверждает эмпирически. Все же у больших языковых моделей присутствует композиционное обобщение, то есть способность собирать вместе «строительные» блоки, которые никогда не собирались вместе. Возможно, именно это и есть суть творчества.
«На самом деле, это и есть оригинальность. Таких вещей никогда не было в мировом учебном корпусе. Никто никогда такого не писал. Это должно быть галлюцинацией», — говорят Арора и Гоял, ученые, которые выдвинули гипотезу.