В условиях крупной промышленной компании с долгой историей и разнородными информационными системами встала задача ускорить цифровизацию и сделать ее управляемой. В НЛМК ИТ выбрали стратегию построения единой технологической платформы, которая объединяет сервисы и процессы и позволяет избежать дублирования решений.
Платформа задумывалась не как набор инструментов «в сферическом вакууме», а как живая экосистема. Она снимает рутинные задачи с продуктовых команд и предоставляет им готовые сервисы и методологии. Это позволяет разработчикам сосредоточиться на бизнес-логике и снижает издержки на интеграцию. В статье Александр Лищук, руководитель платформы сервисов разработки НЛМК ИТ, расскажет о том, что получилось у команды и какие выводы сделали в процессе.

Предыстория
Старт трансформации был связан с объективными сложностями, характерными для промышленных компаний. Системы создавались десятилетиями и сильно отличались на разных площадках, поэтому внедрение единого «коробочного» решения было бы неэффективным и даже рискованным. Многие приложения были критичны для непрерывности производства и не могли быть заменены одномоментно.
Организационная цель платформы заключалась в том, чтобы превратить ИТ из обслуживающего подразделения в полноценного бизнес-партнера. Это означало переход к модели, где ИТ-команды получают возможность экспериментировать, внедрять новые подходы и быстрее выводить функции в промышленную эксплуатацию.
При этом изначально приняли стратегию постепенного распространения ядра платформы, а не жесткого тиражирования по всем площадкам. Такой подход учитывал специфику металлургического производства, наличие закрытых сегментов и гибридность решений: в экосистеме неизбежно соседствуют промышленный софт, legacy-системы и новые сервисы.

Цели и ключевые принципы
Платформа изначально проектировалась вокруг нескольких базовых идей. Первая — смещение ответственности вниз. Общие и повторяющиеся задачи решает команда платформы, а продуктовые команды получают готовые сервисы и практики. Это избавляет компанию от ситуаций, когда ресурсы разных команд тратятся на параллельное создание одних и тех же решений, а также ускоряет запуск проектов.
Вторая идея — продуктовый подход. Каждый сервис должен развиваться как самостоятельный продукт — с понятным портфелем, дорожной картой, метриками и поддержкой пользователей. Такой формат помогает выстраивать прозрачные ожидания и делать развитие сервисов более управляемым.
Третья — ставка на открытые решения. Там, где это оправданно, выбираются open-source-технологии, а команда следует принципу «eat your own dog food» — то есть использует собственные сервисы на равных условиях с другими. Это позволяет сразу проверять качество решений и при необходимости вносить корректировки.
Наконец, в организационном плане платформа строилась как гибрид. Это значит, что, с одной стороны, внутри компании формируются собственные компетенции и готовность дорабатывать решения своими силами. А с другой — сохраняется возможность интегрировать коммерческие продукты и поддерживать широкий стек технологий. Это важно и для внутренних команд, и для подрядчиков: ключевая задача не в навязывании конкретных инструментов, а в обеспечении прозрачности и совместимости.
Архитектура и технологический стек
Архитектура платформы складывалась слоями. На уровне рантайма основой стала оркестрация контейнеров на базе Kubernetes. Для передачи событий и потоков данных используется Kafka. Для хранения и анализа метрик, логов и событий применяется совместимый с OpenTelemetry стек с интеграцией в SIEM для обеспечения требований безопасности.
Инфраструктура управляется по принципам Infrastructure as Code с использованием Ansible и GitOps-подходов. Для оркестрации процессов и автоматизации задействованы AWX, ArgoCD, n8n и пайплайны GitLab. В контуре данных предусмотрены ETL-сервисы и хранилища временных рядов для аналитики и IIoT-решений.
Поверх инфраструктурного уровня формируется технологическая платформа. Она включает self-service-инструменты, прикладные сервисы и клиентскую поддержку, которые позволяют сотням проектов и тысячам пользователей работать в единой экосистеме.
Масштабирование достигается не за счет линейного роста штата, а благодаря автоматизации, шаблонам и встроенным ограничениям. При больших нагрузках — миллионы сообщений в секунду в стриминге или тысячи namespace в кластерах — устойчивость обеспечивается именно за счет такого подхода.
Переход от наставничества к продуктовому формату
На раннем этапе платформа выполняла роль наставника. Команды приходили с вопросами, а инженеры платформы объясняли подходы и предлагали технологии. Такой формат был естественным на старте: стек только формировался, и требовалось сопровождать его внедрение. Со временем ситуация изменилась.
Когда уровень адаптации вырос, платформа стала развиваться как продукт. Теперь команды не только обращались за советом, но и сами формулировали требования к сервисам.
В ответ платформа предлагала готовые решения — шаблоны CI/CD, интеграции, модульные компоненты. Это помогло снизить порог входа: базовые операции были доступны даже при минимальной экспертизе, а для опытных команд сохранялась возможность расширять и кастомизировать сервисы.
Вовлечение происходило «мягкой силой», никто не навязывал переход на платформу, а показывал ее ценность через собственные успешные кейсы. Постепенно демонстрация того, как повторное использование сервисов экономит время и снижает ошибки, убеждала другие команды подключаться.
Важным элементом стал интеграционный цикл: новые инициативы и продукты обсуждались с участием разных команд, и это помогало избежать дублирования, а также стимулировало использование общих компонентов.
В результате начался своеобразный продуктовый бум. В разных цехах и подразделениях появлялись микросервисы и экспериментальные продукты, напоминавшие стартапы. Их авторы все чаще опирались на готовые блоки платформы — таким образом, экосистема росла органично, а практики распространялись не приказами сверху, а через востребованность и доказанную пользу.
Требования к платформенным сервисам
Опыт внедрения показал, что платформенные сервисы должны обладать рядом обязательных свойств. Эти требования сформировались из практических ограничений и рисков, с которыми сталкивались команды.
- Сервисы должны быть самодостаточными. Например, observability сервисы должны уметь собирать метрики и обеспечивать наблюдаемость в гибридных архитектурах, так как пользователи не обязаны переносить свои продукты целиком внутрь платформы.
- Сервисы по умолчанию должны быть простыми в использовании и безопасными. Важно снизить вероятность ошибок, ограничить риск случайных дефектов и при этом предложить готовые сценарии связности: шаблоны CI/CD, автоматическое управление секретами, настройку связей между компонентами.
- Команды должны видеть метрики и логи так, будто сервис развернут ими самостоятельно.
- Сервисы обязаны оставаться в рамках четко определенных соглашений. Платформенная команда не должна превращаться в функциональную команду отдельного продукта. Возможности кастомизации допускаются, но только в управляемых пределах — например, через git-настройки и стандартные механизмы конфигурации.
- Не менее важна изоляция. Экземпляры сервисов разных команд не должны влиять друг на друга. Там, где это возможно, применяются мультитенантные решения. В случаях, когда общий режим не работает, выделяются отдельные ресурсы.
- Особое внимание требуется на ранних стадиях разработки новых сервисов. Каждая функция должна быть тщательно проработана, потому что обратная несовместимость становится серьезной проблемой. Если изменения ломают уже используемый сервис, это превращается в большую головную боль для всех участников. Поэтому на начальных этапах закладывается значительный объем времени на совместное обсуждение и проектирование.
Документация и уменьшение нагрузки на консалтинг
Рост числа сервисов и пользователей платформы неизбежно увеличил поток вопросов к инженерам. Вместо того чтобы развивать платформу, они все больше времени тратили на объяснения и консультации. Решение нашли в двух направлениях — систематической документации и развитии внутреннего сообщества.
Для каждого сервиса оформили четыре типа материалов. Новичкам предлагались вводные туториалы, позволяющие быстро освоиться. Для типовых задач создавались пошаговые инструкции. Отдельный формат посвящался объяснению принципов работы сервисов в контексте компании, включая причины, почему они отличаются от внешнего опыта. Наконец, поддерживались сухие справочники с API, контрактами и описанием ресурсов.
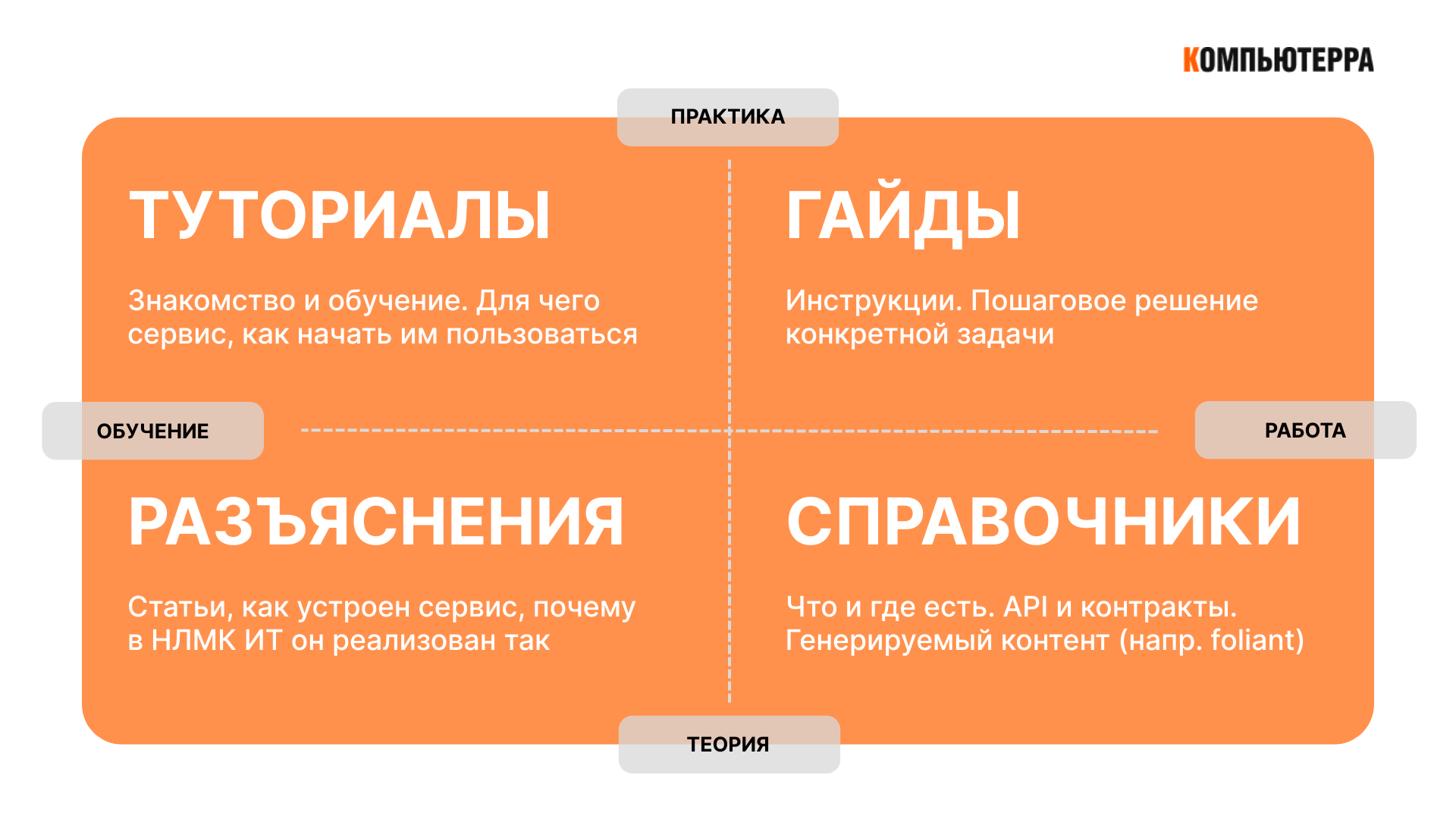
Чтобы снизить объем ручной работы, часть контента начали генерировать автоматически. В пайплайны встроили инструменты, которые собирали данные об источниках, зависимостях и других артефактах, формируя актуальные страницы. Это избавило от необходимости искать информацию в разрозненных README или интерфейсах отдельных сервисов.
Документация поддерживается в двух вариантах: публичная — для пользователей и внутренняя — для самой команды, что снижает зависимость от отдельных специалистов.
Не менее важным направлением стало развитие комьюнити. Команда организует митапы, чаты и гильдии, где пользователи помогают друг другу. Для инженеров это вылилось в снижение нагрузки и рост самостоятельности команд.
Позже добавился инструмент обратной связи, где коллеги оставляют идеи и жалобы, а также голосуют за новые функции. Такой формат сделал приоритизацию развития сервисов более прозрачной и связанной с реальными потребностями.
В результате нагрузка на инженеров заметно снизилась. Все больше вопросов решается с помощью документации и сообщества, а инженеры могут сосредоточиться на доработке сервисов, а не на консультациях.
Автоматизация и self-service
Чтобы платформа могла масштабироваться без пропорционального роста команды, мы с самого начала стали следовать простому правилу: все, что повторяется чаще трех раз в неделю, подлежит автоматизации. Это стало основой подхода к эксплуатации и развитию сервисов.
Архитектурно работу разделили на три слоя. Базовый слой отвечает за инфраструктуру и кластеры. Над ним расположен прикладной конфигурирующий слой — репозитории и инвентари, которые управляют конкретными реализациями сервисов. Третий слой объединяет и компонует предыдущие уровни, позволяя глобально управлять пайплайнами и развертыванием.
Практическими инструментами стали Ansible-инвентари, GitOps-репозитории и API-надстройки: они позволяли коммитить изменения в компонентные репозитории, запускать пайплайны и контролировать автоматизацию. Для часто повторяющихся операций создали MonkeyJob-плейбуки, которые существенно сократили ручную работу инженеров.
Следующим шагом стал портал самообслуживания. Он объединил каталог сервисов и предоставил удобный интерфейс для запросов. Формы с валидацией и нормализацией параметров автоматически запускали операции, а при необходимости предоставляли инженеру шаг Approve/Deny с полным контекстом. Портал интегрировали с ServiceDesk, сохранив стандартный процесс обработки заявок, но переложив значительную часть задач на автоматизацию.
В результате большинство типовых обращений выполняется без участия инженеров, а доля запросов, требующих живого вмешательства, сократилась примерно до одной десятой. Это высвободило время специалистов и позволило сосредоточиться на развитии платформы, а не на рутинной поддержке.
Каталог систем и управление зависимостями
Одним из серьезных организационных вызовов стало объединение данных из разных ИТ-доменов вокруг единого каталога продуктов и систем. Для корректной работы портала самообслуживания и автоматизации требовались сквозные сведения о проектах, их стадиях, бюджетах и зависимостях. Эти данные должны быть доступны по API, чтобы другие сервисы могли использовать их напрямую.
Возникла необходимость в единой идентификации систем и продуктов. Такой подход позволил отслеживать, как прототип превращается в полноценную систему и какие связи при этом образуются. Речь шла не только о классической CMDB, но и о каталогах API-зависимостей и использовании сервисов. Это дало возможность видеть цепочки интеграций и корректно оценивать влияние изменений.
Причем главная сложность заключалась даже не в технологии, а в организационных договоренностях. У каждого ИТ-домена свой взгляд на процессы и приоритеты. Без общей координации появлялся риск теневого ИТ, когда автономные команды решают задачи в обход платформы, потому что считают ее слишком сложной или бюрократизированной. Чтобы этого избежать, потребовались инвестиции в выравнивание процессов и поддержание актуальности данных.
Таким образом, каталог систем и единая идентификация обеспечили сквозную видимость, уменьшили вероятность дублирования решений и позволили платформе оставаться живой и предсказуемой системой.
Дополнительные эффекты и результаты
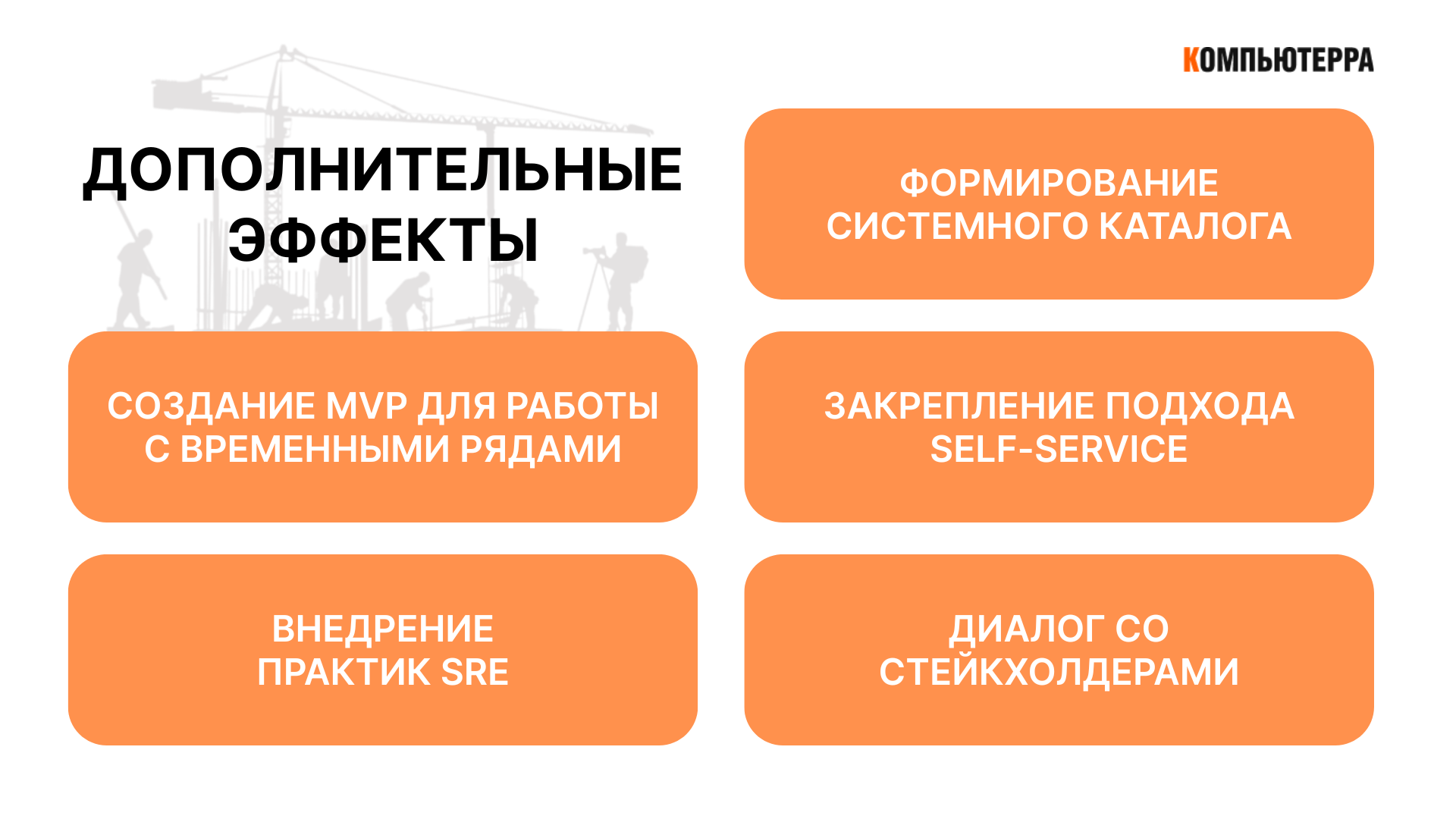
Первым заметным результатом стало формирование системного каталога. Он позволил вести учет активов, систем и проектов в едином формате, упростил управление зависимостями и повысил прозрачность. Это дало дополнительный вес задачам инвентаризации и подтолкнуло компанию к их развитию на более высоком уровне.
Вторым результатом стало создание MVP для работы с временными рядами. На базе платформенных сервисов удалось быстро собрать решение для обработки сырых данных от производственного оборудования. Этот опыт стал основой для полноценной IIoT-платформы.
Третьим эффектом стало закрепление подхода self-service. Идея автоматизации и единой точки входа распространилась на разные домены компании, где начали появляться собственные решения для самообслуживания. Это снизило зависимость от ручных операций и ускорило работу команд.
Кроме того, развитие платформы способствовало внедрению практик SRE. Унифицированные инструменты и процессы, а также стремление к shift-down-модели упростили поддержание высокого уровня доступности систем. На базе платформы появился центр компетенций, который развивает этот подход и помогает снижать риски человеческих ошибок.
Наконец, переход к продуктовому управлению позволил выстроить диалог со стейкхолдерами. Сервисы начали развиваться на основании обратной связи и реальных кейсов, что сделало платформу не просто технологическим решением, а инструментом, встроенным в бизнес-процессы компании.
Резюме
Если в компании много повторяющихся разработок и типовых архитектур, платформенный подход становится не просто оправданным, а логичным. Он позволяет сократить издержки, ускорить внедрение решений и обеспечить предсказуемость в управлении системами.
Опыт НЛМК ИТ показывает, что успешное развитие технологической платформы возможно при сочетании зрелых технологий, продуктового мышления и организационной работы. Платформа должна быть самодостаточной, прозрачной и управляемой контрактами, а ключевой акцент необходимо делать на самообслуживании.
Технический стек и архитектура важны, но сами по себе они не гарантируют успеха. Решающим фактором становится экосистема: документация, развитое сообщество, единый каталог систем и механизм сквозной идентификации. Именно они позволяют платформе оставаться живой системой, поддерживать гибкость и приносить ощутимую экономию времени и ресурсов.
По сути, платформа играет ту же роль, что и фреймворк в разработке. Отдельные инструменты можно использовать и без нее, но, когда количество проектов и команд велико, платформа становится естественным способом упорядочить работу, сократить дублирование и повысить устойчивость цифровой среды.