Рынок искусственного интеллекта ежегодно растет, соответственно увеличивается количество ИИ-проектов в разных сферах. По оценкам Gartner, расходы на глобальном рынке ИИ в 2025 году составили 1,76 трлн долларов, из которых 964,96 млрд пришлось на ИТ-инфраструктуру. В этих условиях компаниям необходимы все более производительные GPU для обучения и инференса моделей. О том, как выбрать графическую карту и подходящую модель под конкретную задачу, рассказывают эксперты Selectel.

Шаг 1. Определите задачу, которую будете решать
Искусственный интеллект выполняет миллиарды вычислений, с которыми обычные процессоры справляются слишком медленно. Десктопные видеокарты зачастую рассчитаны на игры и офисные задачи, тогда как высокопроизводительные GPU позволяют быстро выполнять эти операции и обрабатывать большие объемы данных.
В первую очередь компаниям нужно определить направление ИИ-задач: обучение, файнтюнинг, инференс или все вместе. Только после этого стоит подбирать GPU и ML-модели. Рассмотрим каждую задачу подробнее.
Обучение моделей
Подобную стратегию обычно используют крупные технологические организации, такие как OpenAI и Alibaba. Они самостоятельно настраивают параметры модели с нуля на открытых и собственных датасетах. Обученные модели предоставляют бизнесу большой контроль над архитектурой, данными и характеристиками системы. Это особенно важно в сферах с повышенными требованиями к безопасности.
Важно понимать, что обучение подходит не для всех проектов, поскольку требует значительных ресурсов от компании. Одна только модель GPT-OSS на 120 млрд параметров потратит более 2 млн часов H100 — это эквивалентно 200 серверам HGX H100 или 1 600 GPU H100, которые будут работать 50 дней без перерыва.
Если вы все-таки хотите обучить модель с нуля, ей нужны физические серверы, производительные GPU, системы хранения данных, высокоскоростные сети и инструменты для распределенного обучения. ИИ-инфраструктура должна стабильно работать при длительных нагрузках и обработке большого количества информации.
Кроме того, необходимы высококвалифицированные специалисты, которые умеют обучать и тренировать модели. В их обязанности входят проектирование архитектуры, подготовка данных, настройка гиперпараметров, мониторинг обучения и оптимизация производительности. Затраты здесь носят фиксированный характер.
Обучение моделей с нуля — очень долгий и дорогой процесс. Такой подход оправдан только в том случае, когда компания хочет получить полный контроль над моделью, создать уникальный продукт или заявить о себе в мире ML. В других ситуациях лучше использовать предобученные модели и уже дообучать их на своих данных.
Файнтюнинг моделей
Не всегда компании, которые внедрили ИИ, получают стабильный и предсказуемый результат. Готовые модели не учитывают особенности бизнеса, поэтому могут допускать критические ошибки в цифрах, документах и регламентах. Чтобы повысить точность ответов и минимизировать ошибки, модель дообучают на данных компании через файнтюнинг. Инструмент особенно популярен в специфичных бизнес-сферах — например, в медицине, финансах, юриспруденции и так далее.
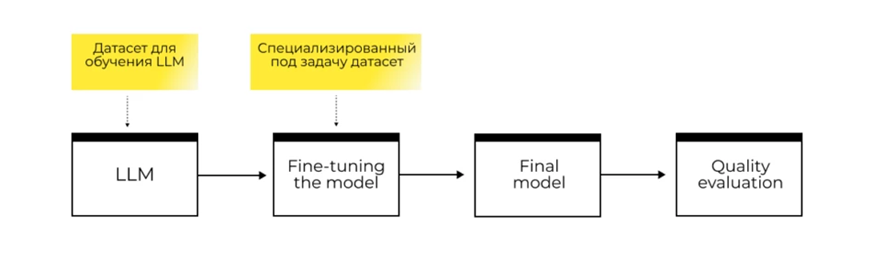
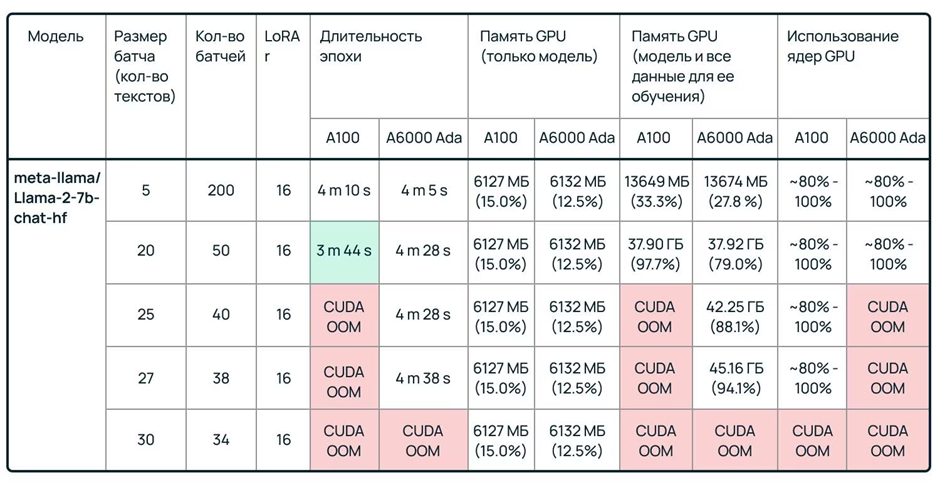
В отличие от обучения, вам не нужно настраивать модель с нуля. Можно взять open source-решение и дообучить его на узкоспециализированном наборе данных. Такой вариант требует намного меньше ресурсов, поэтому подходит даже небольшим компаниям, которые хотят доделать модель под себя. Для сравнения, файнтюнингу достаточно десяти дней работы одного сервера HGX H100, тогда как полному обучению — не менее 200 серверов и 50 дней беспрерывной работы.
Инференс моделей
На финальном этапе компания использует обученную модель для решения реальных задач. Например, применяет голосовых роботов для автоматизации работы колл-центров, чат-ботов для консультаций сотрудников и клиентов, нейросети для распознавания изображений и так далее. Здесь уже не нужно настраивать параметры модели — достаточно взять готовую и сразу ее запустить.
Для инференса ML-моделей необходимо использовать ИТ-инфраструктуру с производительными видеокартами. По такому принципу пошли и мы в Selectel. У компании есть четыре внутренних ИИ-сервиса, которые сегодня сотрудники используют на ежедневной основе:
- Kaken — сервис векторного поиска по внутренней базе знаний;
- Selectel AI — on-premise LLM общего назначения;
- сервис транскрибации и аналитики встреч;
- Copilot для разработчиков.
Чтобы запустить их в продакшен, коллеги взяли за основу языковую модель Qwen3 и развернули ее на серверах с GPU. В планах — дообучить готовую модель на внутренних датасетах, чтобы повысить точность и корректность ответов.
В сценарии инференса вычислительные нагрузки растут вместе с числом пользователей, количеством запросов и размером моделей. Чем выше эти показатели, тем дороже обходится ИИ-инфраструктура с GPU.
Однако вы можете оптимизировать этот процесс с помощью Foundation Models Catalog — сервиса для запуска и управления LLM в облаке. Платформа самостоятельно разворачивает модель на подходящей инфраструктуре и выдает эндпоинт с токеном доступа.
Дополнительные задачи
Помимо ИИ-задач компании используют GPU для 3D-рендеринга, транскодирования видео и обработки изображений, а также для HPC и научных вычислений. Эти сценарии обычно требуют меньше вычислительных мощностей, чем обучение и инференс моделей.
Шаг 2. Выберите ML-модель под задачу
От выбранной модели зависят требования к оборудованию: чем больше и сложнее модель, тем мощнее нужна видеокарта. При этом все модели отличаются друг от друга. Основные различия — по тому, как они сделаны и какая у них эффективность. Например, DeepSeek использует меньше ресурсов относительно своего размера и работает эффективнее по сравнению с моделями того же класса.
В таблице собрали популярные ML-модели с параметрами и ресурсами.
|
Задачи |
Модели | Параметры | VRAM |
GPU |
| Простой чат-бот с простым ответом | Qwen3-8B
DeepSeek-V2 gpt-oss-20B GigaChat3-10B |
7B–20B | 8–24 GB | RTX 3070, RTX 3090, RTX 4090, A2, T4 |
| Сложный чат-бот с поиском / поиск по документации | Qwen3-30B/80B
DeepSeek R1 Distilled gpt-oss-120b |
30B–80B | 48–80 GB | RTX 4090, A5000, A100, H100, H200 |
| Распознавание и обработка документов | DeepSeek-OCR
Qwen3-VL |
8B–16B | 8–24 GB | RTX 3090, RTX 4090, L4, T4 |
| Общий ИИ для сложных задач | Qwen 3.5, DeepSeek V3.2, Kimi K2.5 | 30B–300B и выше | 48–288 GB | RTX 4090, A100, H100, H200 |
| Дообучение небольших моделей под ваши задачи | Qwen 3,
gpt-oss-20b |
7B–30B | 24–80 GB | RTX 4090, A5000, A100, H200 |
| Полноценное обучение моделей или дообучение сложных | Практические любые | 30B+ | 160 GB+ | H100 , H200, B300 |
Для инференса обычно используют крупные модели, такие как DeepSeek V3.2, Qwen3-235, GPT-OSS-120B. Они гарантируют высокую точность ответов и быстро обрабатывают даже самые большие объемы данных. Маленькие модели — qwen3 30B, Mistral, Gemma — подходят для обычных или менее ресурсоемких задач. Они требуют меньше вычислительных мощностей и памяти, работают быстрее и экономичнее.
Полный список доступных моделей можно посмотреть на Hugging Face.
Шаг 3. Подобрать конфигурацию GPU
Выбор подходящей GPU для машинного обучения зависит от конкретных задач, бюджета и требований к производительности. Рекомендуем обратить внимание на несколько ключевых параметров.
- Объем памяти. Небольшим проектам или задачам обычно хватает 8–16 ГБ. Однако для инференса больших моделей или глубокого обучения подойдут GPU от 24 ГБ и выше, вплоть до 144 ГБ.
- Пропускная способность памяти. Обеспечивает высокую производительность в задачах, которые требуют быстрой передачи больших объемов данных. Для машинного обучения и инференса моделей рекомендуем выбирать GPU с пропускной скоростью от 500 ГБ/с.
- Поддержка NVLink. Объединяет видеокарты в кластерные решения, чтобы увеличить доступную память и скорость обмена данными. В первую очередь NVLink нужен для обучения моделей, тогда как для инференса не критичен.
- Вычислительная мощность. Измеряется в TFLOPS (терафлопс). Чем выше этот показатель, тем быстрее выполняется обучение моделей.
Рекомендуем заложить небольшой резерв по ресурсам на случай, если нагрузка на сервер или количество запросов увеличатся.
Видеокарты NVIDIA закрывают все задачи, связанные с инференсом, файнтюнингом и обучением AI-моделей. Самые популярные из них — от самых производительных к менее — представлены в таблице.
|
Задачи |
Видеокарта | Характеристики |
Особенности |
| Обучение, инференс и файнтюнинг | NVIDIA DGX B300 | 2 ТБ HBM3E
FP4 — 144 PFLOPS, FP8 — 72 PFLOPS 8 ТБ/c пропускной способности |
Подходит для больших моделей с триллионами параметров без шардирования и HPC.
Поддерживает большое количество одновременных запросов. |
| Обучение, инференс и файнтюнинг | NVIDIA H200 | 141 ГБ HBM3E
FP64 — 34 TFLOPS, FP32 — 67 TFLOPS 4,8 ТБ/с пропускной способности |
Подойдет для моделей среднего и большого размера. |
| Обучение, инференс и файнтюнинг, а также работа с графикой и рендеринг видео | NVIDIA RTX PRO 6000 | 96 ГБ GDDR7 ECC
FP8 — 3120 TFLOPS, FP16 — 780 TFLOPS 1,8 ТБ/с пропускной способности |
Подойдет для моделей среднего и маленького размера.
Решает практически любые задачи, но сильно уступает задачам с ИИ. |
| Обучение, инференс и файнтюнинг небольших моделей | NVIDIA H100 | 80 ГБ HBM3
FP8 — 3958 TFLOPS, FP64 — 51 TFLOPS 3 ТБ/с пропускной способности |
Специализируется на AI-задачах. Рендеринг выполняет хуже и дороже. |
| Работа с графикой и рендеринг видео, а также инференс небольших моделей | NVIDIA RTX 4090 на 24 и 48 ГБ | 24 и 48 ГБ GDDR6X
FP16 — 82,58 TFLOPS 1008 ГБ/с пропускной способности |
Выгоднее PRO 6000, при этом выполняет похожие задачи.
Подойдет для небольших моделей. |
| NVIDIA RTX A5000 | 24 ГБ
768 ГБ/с пропускной способности FP32 — 27,77 TFLOPS, FP16 — 27,77 TFLOPS |
По возможностям напоминает RTX 4090, но дороже. Разница между ними — в цене. |
Для удобства вы можете арендовать серверы с GPU для ML и AI-задач. Профессиональные видеокарты подойдут для обучения нейросетей, решения сложных AI-вычислений, ускорения рабочих нагрузок и инференса.
Резюме
Инференс, обучение и файнтюнинг отличаются по нагрузке и требованиям к ИТ-инфраструктуре, поэтому при выборе GPU нужно опираться не на самую мощную модель, а на конкретную AI-задачу.
Для обучения моделей подойдут такие решения, как H100, H200, B300 или HGX. Для файнтюнинга и инференса моделей будет достаточно RTX PRO 6000 или RTX 4090. При этом важно заранее учитывать рост нагрузки, чтобы спустя время инфраструктура не потребовала срочного апгрейда.
Оптимальный подход — сначала определить сценарии использования AI, затем выбрать конкретную модель и только после этого конфигурацию GPU. Такой порядок позволит избежать лишних затрат и обеспечит стабильную производительность под реальные задачи бизнеса.