

Задача отличить вычислительную машину от человека до недавнего времени была чисто развлекательной. С лёгкой руки Алана Тьюринга, семь десятилетий назад придумавшего свой тест, и до сего дня конечная цель всех попыток сделать это — то есть построить компьютер, неотличимый от Homo sapiens, или распознать компьютер, под Homo sapiens маскирующийся — сводилась единственно к возможности заявить: да, мы смогли! Практического применения не просматривалось. Однако в этом году вдруг валом повалили сообщения — и не только из лабораторий, а уже и из производственных цехов — о решении некоторых разновидностей знаменитого теста с прицелом именно на практическое применение. Обозначился и круг новых проблем и перспектив, с такими решениями связанных. Что изменилось? Да просто машины, научившиеся имитировать человека очень хорошо, стали работать с нами бок о бок…
Пусть не мыслящие по-настоящему, пусть не эквивалентные нам интеллектуально, но имитирующие нас настолько качественно, что разницу заметить нелегко, такие компьютеры теперь участвуют в нашей жизни каждый день. Прежде всего это суперкомпьютеры, использующие алгоритмы глубокого обучения для предугадывания поисковых запросов в интернет-поисковиках, формирования лент новостей в соцсетях, обработки фотографий в «облачных» сервисах. Чтобы решать подобного рода приземлённые задачи, не требуется удовлетворять тесту Тьюринга (который, сильно упрощая, таков: машина должна доказать, что она человек). Однако качество имитации неожиданно оказалось столь высоким, а её возможные последствия столь значительными, что нам, то есть пользователям, стало необходимо знать, кто работает на «том конце провода»: компьютер или живое существо.
Вообразите ситуацию: есть подозрение, что под видом «умной» машины в некоем интернет-сервисе на самом деле работает человек. Есть ли способ выяснить правду? Есть ли у машины возможность доказать, что она машина?
Ситуация… странная. Но взгляните на неё под таким углом. Пусть компании, владеющей крупным интернет-почтовиком, захотелось написать интеллектуального бота, который помогал бы пользователям писать письма. Для этого нужен доступ в почтовые ящики — и компания его, конечно, своим разработчикам предоставляет. Втихую, никого не известив, ни у кого не спросив разрешения. Да и зачем что-то спрашивать? Ведь речь всего лишь об обработке писем машиной, то есть программой с элементами искусственного интеллекта. Беспокоить пользователей по этому поводу — всё равно что дёргать их каждый раз при запуске новых спам-фильтров! Вот так и продолжается несколько лет, пока пронырливые журналисты не узнают, что на самом деле почту читают не машины, а люди. Которых наняли, чтобы они выполняли работу ИИ.
Почему нанимали людей? А потому что так дешевле! Есть даже такая шутка: хочешь организовать революционный ИИ-стартап — найми индусов, которые будут имитировать ИИ задёшево, и жди, пока ИИ с нужными функциями изобретут. И правды в этой шутке куда больше, чем хотелось бы. И чем это чревато, помимо уставших от тупого механического труда людей, тоже понятно: через человека, например, могут утекать персональные данные (всё, что можно переслать в почте: пароли, криптоключи, интимные фото и т.п.). Не факт, что утекут, но могут! А значит стоит как минимум поставить в известность пользователей почтовика: желают ли они предоставить доступ к своим письмам роботам и, возможно, людям, чтобы помочь построить и натренировать ИИ?
История эта не выдуманная. Я лишь упростил её для наглядности, а вообще-то она на самом деле случалась несколько раз за последние годы — и в разгорающемся сейчас скандале звучат такие имена, как Google, Facebook, Microsoft, X.ai и другие. В какой-то период своей деятельности все они использовали людей вместо ИИ, не утруждаясь объяснениями. Так что задача отличить человека от машины, дать последней доказать своё «электронное Я», вдруг оказалась очень даже нужной. Вопрос: возможно ли это?
Ясное дело, доказывать придётся автоматически, а значит оригинальный тест Тьюринга не годится (его «исполняет» человек). Но оказалось, что это даже упрощает задачу. Вот вам пример готового сервиса для автоматического отделения машин от людей: HumansNotInvited.com. Правда, выглядит знакомо? Напоминает капчу: набор картинок, из которых нужно выбрать только содержащие нужные объекты. Капчей отделяют людей от машин, здесь же принцип реализован с обратным знаком: это антикапча — для отделения машин от людей!
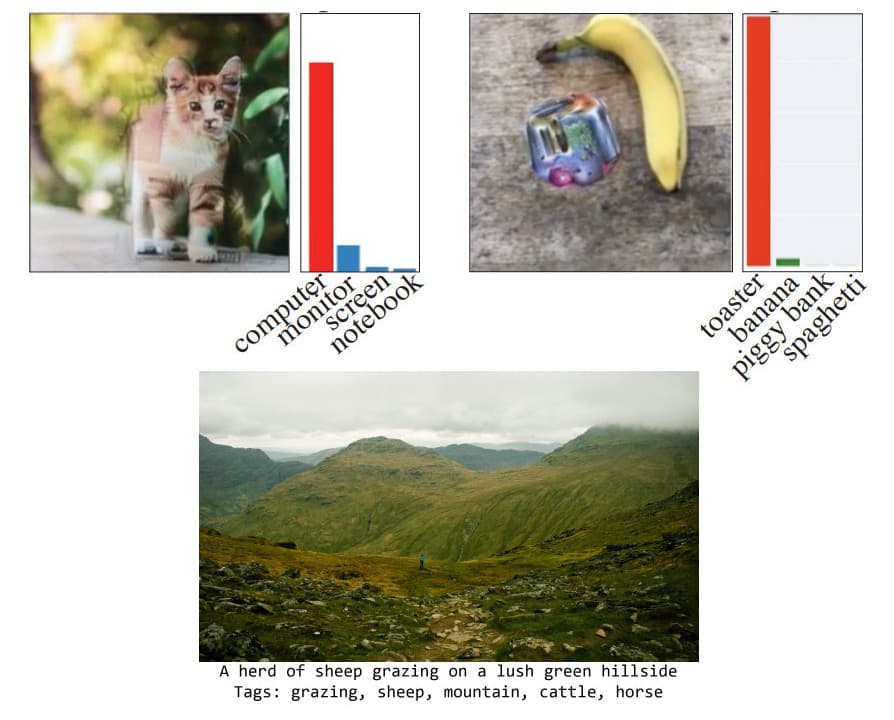
Сильно упрощая, дело тут в том, что рекуррентные искусственные нейросети, на которых строят ИИ-системы, распознают образы не так, как человек. Анализируя, скажем, изображение, они тоже ищут в нём знакомые элементы, но другие и группируют их иначе. В результате они порой видят «странное», то есть (на наш взгляд) ошибаются. Вот примеры таких «ошибок»: натюрморт из банана и странного цветного пятна, понимаемый ИИ как «тостер», фотография котёнка, понимаемая как «системный блок и монитор». Зелёные луга, на которых ИИ почему-то видит овечек. А вот целая научная работа, в которой разбирается, почему изменение всего одного пикселя во многих изображениях способно радикально повлиять на то, что ИИ увидит.
Эта забавная способность «нести чушь» давно и с даже с некоторым успехом используется в экспериментах с ИИ-творчеством (вспомните: «Как ИИ кино снимал»). Однако в нашем случае важен сам факт того, что машины видят окружающий мир иначе, видят иногда то, чего мы сами увидеть не можем. Осталось лишь сформулировать, поймать такие моменты, и поставить машине задачу сказать: что она увидела?
Вот так и работает антикапча. Попробуйте её пройти! Вам предложат несколько мутных квадратов, из которых нужно выбрать, например, содержащие кошек или собак. И вы, конечно, провалитесь — потому что изображения здесь лишены элементов, распознаваемых человеком. Максимум, что вы сможете сделать, это попробовать догадаться о смысле картинки по косвенным признакам: цвету, яркости, ориентации пятен. А вот искусственная нейросеть с задачей справится — обнаружив объекты по знакомым деталям, которые она выделила в ходе тренировки на сотнях тысяч изображений.
Таким образом при необходимости машина может доказать, что она машина — и это бывает полезным. Но что делать в ситуации, когда машина не желает быть раскрытой? Когда машина имитирует человека настолько хорошо, что человек «на этом конце» убеждён, что общается с человеком?
Но разве это возможно, если тест Тьюринга полностью пока не пройден? Действительно, в полной мере он не пройден. Но вот в частностях, в сценариях с ограниченным диапазоном вариантов, машина уже способна имитировать нас очень убедительно. И задача поэтому: автоматически распознать машину, когда она не желает быть распознанной. Есть ли решения у этой задачи?
Для наглядности давайте снова возьмём пример из жизни. И хотим мы того или нет, это снова приведёт нас в Google. Постоянные читатели вспомнят, как пару лет назад в научно-популярных СМИ проскочила сенсация: задействовав глубокое обучение, исследователям удалось синтезировать человеческий голос настолько натуралистичный, что в слепых тестах испытатели оценивали его даже выше человеческого (проект WaveNet; см. «Говорить как человек, говорить лучше человека!» и «Голос — больше не улика»). Тогда это казалось достижением на уровне дробления элементарных частиц и полётов к Марсу — в том смысле, что практического применения не предвиделось долго. Но неожиданно быстро новому синтезатору нашли именно практическое применение.
Дополнив WaveNet элементами ИИ для распознавания речи, Google выдала продукт, демонстрация которого устроила уже настоящую, без всяких оговорок, сенсацию. В мае текущего года «умный» помощник Google Assistant, используя технологию синтеза речи, названную Google Duplex, по просьбе пользователя самостоятельно записал этого самого пользователя в парикмахерскую и ресторан. Да, как выяснилось позже, то была лишь демонстрация, то есть в реальности, вероятно, Duplex сработает не так чётко. И всё-таки — факт: уже этим летом на рынке появится программный продукт, имитирующий человеческий голос и манеру вести диалог с почти абсолютной достоверностью. И столкнуться с ним, став его невольным собеседником, имеет шансы каждый.
Признайтесь, вы испытали сейчас укол страха: не так-то приятно, поболтав по телефону, узнать, что говорили вы не с человеком и почувствовать себя… обманутым, введённым в заблуждение! Собственно поэтому вопрос, следует ли обязать Google Duplex и вообще ИИ называть себя («Здравствуйте, я робот…»), спровоцировал бурную и весьма острую дискуссию.
Что если ИИ не представится? Во-первых, он (то есть его разработчики, владельцы или пользователи, конечно) нарушит закон: во многих странах, начиная запись телефонного разговора, требуется об этом собеседника предупредить (в том числе чтобы собеседник понимал опасность утечки сообщённых в ходе разговора сведений). Google Duplex, естественно, разговор «пишет» (и для анализа в ходе диалога, и для тренировки в дальнейшем), но об этом не упоминает. Во-вторых, подмена человека роботом, с явным намерением подмену скрыть, рассматривается некоторыми юристами как введение в заблуждение, то есть, в общем, тоже криминал. Наконец, в-третьих, голос персоны, которой Duplex позвонил, без спросу используется для улучшения программного продукта, к которому данная персона отношения не имеет.
Всё перечисленное можно списать на формализм, но очень много кто вот так просто махнуть рукой и забыть о вероятных опасностях не готов. К слову, сама Google, после нешуточной перепалки в СМИ и соцсетях, пошла на уступки: пообещала, что Duplex будет идентифицировать себя и предупреждать, где это требуется, о ведении записи. Однако это не сняло вопроса, поставленного выше. Ведь однажды всё равно найдётся компания или индивид, которые заставят ИИ имитировать человека без уведомления. Так можно ли распознать машину, когда она не желает быть распознанной?

Спрашивать её о смысле сущего бесполезно: даже довольно тупых ботов, вроде Siri, давно научили ответам на избитые вопросы. Уповать на закон можно (создать такой ИИ не просто и разработчик, конечно, предпочтёт закону не перечить), но гарантий это не даёт. Пытаться заставить пройти антикапчу бессмысленно: машина уж конечно соврёт, то есть умышленно завалит тест! К счастью всё-таки существует подходящее техническое решение, опирающееся на распознавание образов. Оно, впрочем, только начинает прорабатываться, поэтому объясню, как смогу — и если среди читателей найдутся специалисты, буду благодарен за дополнения в комментариях.
Так вот суть в том, чтобы заставить ИИ, распознавая образы, заодно выполнить некоторую незапланированную работу и тем выдать себя. Попросту говоря, предоставив машине на анализ несколько изображений, возможно незаметно для неё и независимо от её намерений и «желаний» получить в результатах математические свидетельства того, что обработкой занимался именно компьютер, а не человек.
В простейшем случае можно внести в изображения небольшие, особым образом подобранные искажения, которые радикально повлияют на то, что машина «увидит» (вспомните указанную выше работу: всего одна лишняя точка на снимке лошади не помешает человеку увидеть лошадь, а вот ИИ, сам того не подозревая, сообщит, что увидел лягушку). Но разрабатываются и более сложные алгоритмы, с несколькими изображениями, содержимое которых взаимосвязано.
Таким образом чисто математически решение есть: даже если машина не желает быть раскрытой, её можно распознать. Но проблема, неожиданно (снова и снова!) преградившая здесь путь, правовая. Если мы заставляем компьютер выполнить что-то, на что его владелец не давал согласия, не следует ли считать это взломом? Да, речь уже не о простом программном обеспечении, но суть-то ведь не изменилась: мы эксплуатируем слабое место в искусственной нейросети, которая, суть, тоже программа. С некоторыми оговорками этот печальный вывод распространяется и на антикапчу.
Как эта дилемма будет решена, предсказывать не возьмусь. Одно несомненно: решать её придётся. Ведь машин, слишком похожих на человека, рядом с человеком с каждым днём всё больше.