В первой части статьи мы рассказали об истории появления больших данных и дали определение этому термину, теперь рассмотрим примеры и области применения, а также поговорим о технологиях, которые используются в Big Data.
Вступление
Доклад о проблемах, связанных с 3V, вышел в свет неспроста. Уже в конце 90-х годов такие индустрии, как поисковые системы, анализирующие и улучшающие свои алгоритмы; маркетинговые компании, начинающие собирать все возрастающий объем данных о поведенческой модели своих потенциальных покупателей; исследовательские агентства, такие как NASA, консолидирующие информацию с тысяч своих устройств, столкнулись с описанными в этом докладе трудностями. Существующих решений уже не хватало, чтобы справиться с увеличивающимися потоками данных, которые все чаще выходили далеко за пределы оперативной памяти отдельных решений, поэтому подход с вертикальным масштабированием больше не обеспечивал нужды бизнеса. Требовались новые подходы, и мир нуждался в новых технологиях хранения и анализа информации. Технологиях отказоустойчивых и хорошо масштабируемых горизонтально. И они не заставили себя долго ждать.
MapReduceи GFS
В 2004 году корпорация Google в лице Джеффри Дина и Санжая Гемавата представила миру на удивление простой, но невероятно действенный подход к обработке огромного количества информации. По сути, данный алгоритм позволял работать с неограниченным объемом данных при условии возможности наращивания новых кластерных нод пропорционально увеличению количества обрабатываемой информации.
Как можно понять из названия, алгоритм сводился к разбиению процесса обработки на две простые функции – Map и Reduce, причем единую задачу мы можем разбить на бесконечно большое количество малых подзадач, которые будут выполняться параллельно друг с другом, а потом просто сложить полученный результат. Каждую часть одной большой задачи можно отдать на обработку одному из узлов единого кластера и все, что нам останется при увеличении объемов информации, – это расширить кластер до необходимых нашей задаче размеров.
Давайте попробуем понять подход MapReduce на простейшем примере. Допустим, нам нужно посчитать все упоминания Ивана Иванова, Петра Петрова и Андрея Андреева на всех страницах в Интернете. Потребуется проанализировать огромнейший объем информации, и для одного узла такая задача просто непосильна. Но используя подход MapReduce, мы можем разделить все страницы на части и распределить их анализ на разные ноды нашего кластера.
На первом шаге данные со страниц будут отданы в функцию Map, которая при наличии совпадения вернет нам пары «ключ – значение». В нашем примере это будет (Андрей Андреев, 1), (Петр Петров, 1), (Иван Иванов, 1). То есть при каждом нахождении упоминания нужных людей, мы будем получать от функции Map ключ (Имя Фамилию в нашем случае) и значение, которое в нашем примере свидетельствует об обнаружении упоминания. В итоге мы можем получить следующую картину:
* (Андрей Андреев, 1)
* (Иван Иванов, 1)
* (Петр Петров, 1)
* (Андрей Андреев, 1)
* (Иван Иванов, 1)
Отлично! Мы отделили зерна от плевел и теперь готовы саккумулировать полученную информацию путем передачи ее в функцию Reduce, которая так же вернет нам на выходе пары «ключ – значение», но уже в обработанном виде:
* (Андрей Андреев, 2)
* (Иван Иванов, 2)
* (Петр Петров, 1)
Готово! На входе мы можем получить терабайты информации, раздробить ее обработку на узлы нашего кластера и с помощью алгоритма MapReduce получить нужные данные.
Эта технология стала отправной точкой для создания систем, работающих с Большими Данными и стала чем-то вроде стандарта de facto при разработке решений в области Big Data. Такой подход помог компании Google повысить эффективность своего поискового ресурса и распараллеливать линейные задачи при работе с петабайтами данных. На своей заре MapReduce использовался Google как средство оптимизации индексирования данных для поисковых запросов. Но как хранить эти данные, а главное – как их быстро находить и обращаться к ним, если они размещены на тысячи серверов?
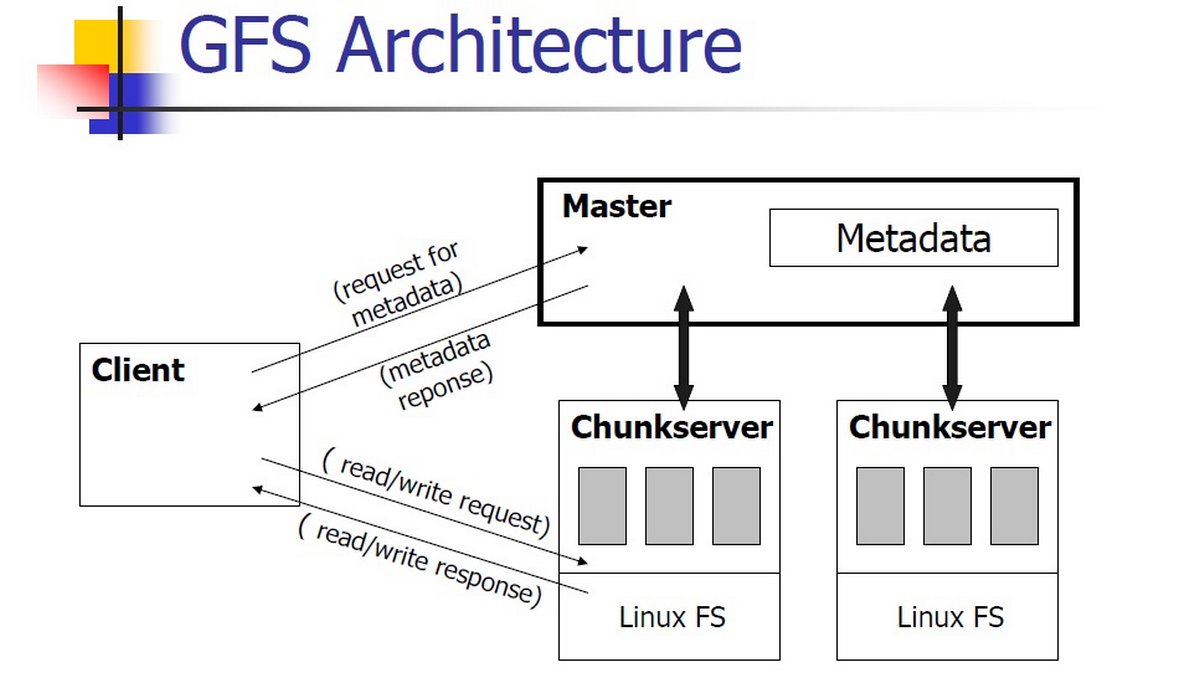
Для этих целей Google использовал свою же разработку – распределенную файловую систему GFS (Google File System), которая в качестве единицы хранения использовала так называемые чанки, имеющие определенный размер и несущие в себе информацию. Все серверы, входящие в кластер GFS, можно представить как один большой жесткий диск, в отличие от которого, информация о расположении того или иного блока данных (чанка) хранится на отдельных мастер-серверах, постоянно держащих в оперативной памяти метаданные, что позволяет оперативно обращаться именно к нужной части кластера. Для достижения избыточности копия одного чанка хранится на нескольких серверах, а мастер-сервер рассылает снимки своей оперативной памяти на подчиненные серверы, в любой момент готовые развернуть снимок в своем пространстве и перехватить роль мастера.
Данный подход имел и узкое место. Им являлся мастер-сервер, ведь с ростом количества информации и введением в работу новых сервисов, далеко выходивших за рамки задачи поисковика и требующих околонулевые задержки при работе с данными, мастер-сервер мог упереться в порог своего вертикального роста. Google решила данную проблему с выходом GFS 2.0 под кодовым названием Colossus, сделав сервер метаданных распределенным. Это было особенно актуально ввиду уменьшения размера чанка и увеличения из-за этого объема метаданных на мастер-серверах.
Несмотря на то что мы крайне поверхностно затронули эти технологии, мы все же можем представить общую картину, которую нарисовал нам Google в 2003–2004 году и которую можно в полной мере назвать Big Data. На этой картине присутствуют тысячи серверов, хранящие петабайты данных, расположенных в виде чанков на файловой системе, единой для всего совокупного пространства серверов, с возможностью молниеносного поиска чанка с необходимой информацией через мастер-серверы. А дальше в бой вступают работники Map, действующие параллельно, получающие из данных «ключ – значение» и отдающих их труженикам Reduce, которые сводят полученную информацию в единое целое.
Такой подход дал быстрый старт развитию технологий, связанных с большими данными. После поисковых систем эстафету стали перенимать социальные сети, интернет вещей, банковский и научно-исследовательский сектор, а также все сферы бизнеса, в которых внедрение технологий Big Data давало ощутимые преимущества над конкурентами.
Hadoop
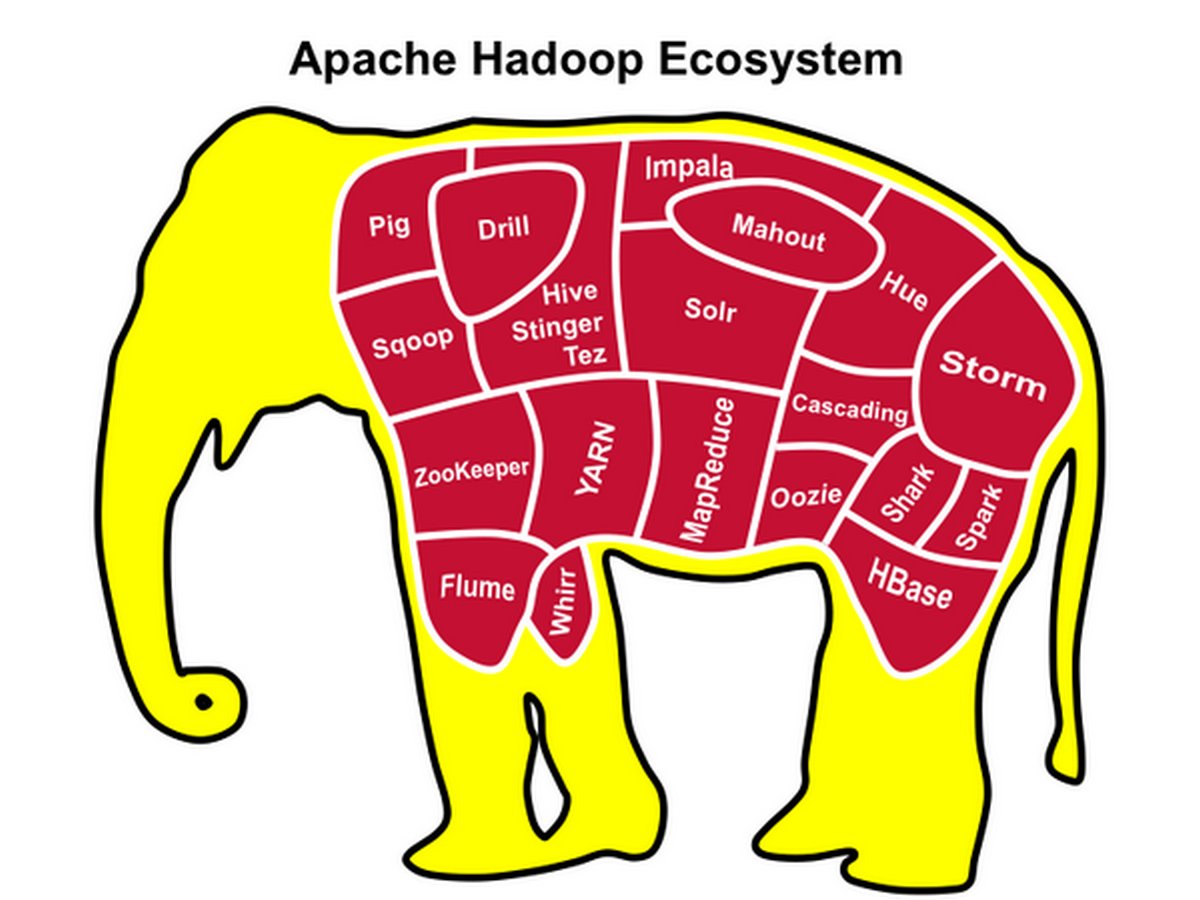
Как мы упомянули выше, разработанная Google концепция быстро подстегнула интерес сообщества к распределенному хранению и анализу информации. Несмотря на то что Google не раскрыла никакой точной информации о работе своих технологий, вскоре стали появляться аналогичные реализации данного подхода, и главной из них, без сомнения, является Hadoop, разработка которого началась практически сразу после доклада Google о вычислительной модели MapReduce. Работа над проектом изначально велась силами всего двух разработчиков: Дугом Каттингом и Майком Кафареллом. Предтечей Hadoop был проект Nutch, в котором Дуг Каттинг пытался решить проблему больших данных в сфере поисковых систем, но его архитектура не позволила этого сделать.
Глотком свежего воздуха для Каттинга и послужил доклад об алгоритме MapReduce. В 2006 году его пригласили возглавить команду разработчиков в Yahoo для реализации системы распределенных вычислений, в результате чего и появился проект Hadoop, названный так в честь игрушечного слоненка сынишки Дуга Каттинга. Через два года Hadoop управлял распределенной поисковой системой, развернувшийся на 10 000 процессорных ядрах. Тогда же Hadoop вошел в состав Apache Software Foundation. Основой Hadoop, как и в случае с Google, является распределенная файловая система HDFS и алгоритм распределенных вычислений Hadoop MapReduce.
После явного успеха поисковой системы Yahoo, основанной на Hadoop, технологию стали применять такие компании, как Amazon, Facebook, NewYork Time, Ebay и многие другие. Успех Hadoop был настолько ошеломляющим, что его бросились коммерциализировать как основные, так и новые игроки рынка. Первой золотую жилу начала осваивать компания Cloudera (куда позже перешел Каттинг), за ней подтянулись MapR, IBM, Oracle, EMC, Intel и другие. Yahoo вывела отдел разработки в отдельную компанию Hortonworks, позже писавшую реализацию Hadoop для Microsoft. Решение проблем литеры V сдвинулось с мертвой точки.
Но не все так красиво на практике, как может показаться на бумаге. У классической реализации MapReduce есть один очень существенный нюанс: вся цепочка результатов работ воркеров Map-Reduce сохраняется в дисковую подсистему. А так как данный процесс намного сложнее, чем мы описали в нашем примере, операций чтения-записи будет действительно много, что не может положительно сказаться на времени работы алгоритма. Эти проблемы частично устранили такие решения, как Spark, переводящие бОльшую часть вычислений в оперативную память. После появления данной концепции многие пользователи Hadoop начали активно ее использовать, уходя от узкого места производительности дисковых подсистем.
На примере Spark становится ясно, что MapReduce, являясь первопроходцем в алгоритмах распределенного вычисления, стал уступать позиции другим подходам в этой области. Еще один подход, под названием Tez, использующий графы, разработала вышеупомянутая Hartonworks.
SQLorNO?
Ложка хороша к обеду. Именно так можно кратко ответить на споры по поводу выбора модели баз данных. Если не вдаваться в подробности, то SQL-модель, или реляционная, организует хранение данных в плоских таблицах, каждая строка в которой заполнена свойствами. Она хорошо структурирована, мы заранее определяем схему хранения, и данные в рамках этой схемы однотипны.
В NoSQL подход иной. С первого взгляда она хаотична, ведь рядом с текстом в ней могут находиться картинки, ключи, значения и прочие разнотипные данные. Нам не нужно заранее создавать и определять схему хранения, чтобы заносить в базу данных информацию. Ее структура либо динамична, либо полностью отсутствует.
Решения всегда подбираются исходя из задач и очень часто комбинируются исходя из типов данных, которые необходимо хранить, скорости и объема их прироста, структурированности, требований к дальнейшей их обработке и других критериев.
В экосистеме Hadoop из SQL-решений встречаются следующие: Hive, в котором в итоге отказались от парадигмы MapReduce в пользу вышеуказанного Tez; Spark SQL, Impala, тоже не использующий разработку от Google, но, в отличие от Hive, изначально реализующий собственную разработку алгоритма распределенных вычислений.
Из NoSQL – HBase. Это децентрализованная база данных позволяет добиться огромного профита производительности за счет своего метода работы. Она собирает данные в оперативной памяти по достижении определенного лимита и только затем пишет данные на HDFS.
Но не hadoop’ом единым… Спектр технологий, которые можно смело отнести к Big Data, сейчас настолько широк, что проблематично даже в двух словах рассказать о каждом из них. Это и SAP Hana, которая ввела в оборот новое выражение – NewSQL – и использует в своем арсенале подход in-memory. Это и log-аналитики типа Splunk и InTrust. Это Яндекс clickhouse, который показал, насколько быстрой может быть обработка данных. Druid, HP Vertica, Calpont и десятки других технологических продуктов помогают управлять большими данными в различных задачах.
Ареал обитания Big Data
Опустим описание альма-матер больших данных – поисковых систем, кроме них сегодня трудно встретить отрасль, где использование технологий Big Data в том или ином виде не принесет положительный результат. В коммерческом секторе эти системы зачастую выполняют роль создателя портрета потенциального клиента с целью персонализировать, таргетировать рекламу. Вряд ли пентхаусы в центре Москвы заинтересуют 18-летнего студента без постоянного дохода или краска для волос вдохновит на покупку лысеющего инженера 50 лет. Big Data вывела информированность бизнеса о людях на один уровень со спецслужбами. Благодаря этому уже не секрет, какое молоко вы покупаете, как часто ходите в магазин, какой средний чек, где отдыхаете, ваш примерный (поверьте, почти точный) уровень дохода и прочие мелочи, которые, попадая в аналитический котел систем Big Data, связывают неструктурированную информацию воедино и получают невероятно приближенный к действительности ваш портрет. А потом всего лишь останется в нужное время показать вам то, что вы так давно намеревались купить, но все не решались.
Но таргетированная реклама – далеко не единственный инструмент бизнеса по увеличению роста продаж. Благодаря технологиям Big Data компании проводят репутационный анализ, обрабатывая комментарии пользователей в социальных сетях, на торговых площадках, форумах и других ресурсах. Карточки потенциальных клиентов пополняются списком их активности на этих ресурсах, проводится поиск и сопоставление «левых» аккаунтов, анализируется негатив и многое другое. Большие данные стали в прямом смысле двигателем торговли.
Банковский сектор тоже активно использует аналитику больших данных в своих процессах для привлечения клиентов, а также в сфере информационной безопасности. С недавнего времени начали работать скоринговые системы, рассчитывающие риски при кредитовании. Сбербанк начал анализировать активность клиентов и на основе этих данных прогнозирует нагрузку на отделения, автоматизируя при этом управление персоналом.
Как мы упоминали в первой статье, интернет вещей сейчас выходит далеко за рамки умного дома. Это еще одна отрасль, которую изменила Big Data. Умные фабрики, умные склады, данные о пробках, анализ тысяч параметров на производстве и на точках добычи полезных ископаемых – все это часть IoT. В сельском хозяйстве большие данные позволяют быстрее выводить новые сорта, по загруженным фотографиям больных растений предотвращается гибель урожая, и это лишь пара примеров из множества.
Не обойдем мы вниманием и Илона Маска, чья Big Data собирает по 30 ГБ информации с каждой модели Tesla, в результате чего будет сформирована модель для обучения беспилотных автомобилей.
Здравоохранение – одна из перспективнейших отраслей для внедрения технологий Big Data. Уже сейчас поисковые системы на основе увеличения запросов по тем или иным болезням дают нам возможность предупредить эпидемию. Экспериментальные модели по диагностированию активно разрабатываются, и мы верим, что недалек тот день, когда постановка диагноза будет практически полностью автоматизирована.
Фундамент больших данных
Невозможно построить систему такой сложности без прочной опоры под ногами, которой традиционно выступают системы хранения данных и сопутствующие технологии.
Как же они помогают работать с большими данными? Ряд из них крайне эффективно помогает бороться с проблемами «литеры V», которые с ростом объемов информации не собираются уходить на второй план.
К примеру, для компании Healthcare Association инженеры из NetApp на базе линейки E-series развернули систему для работы с базой данных в 200 терабайт, производительность которой при работе алгоритма MapReduce на архитектуре Hadoop оказалась в два раза быстрее систем с локальным хранилищем. Система показала себя крайне устойчивой к отказам и легко поддающейся масштабированию, а уменьшение количества копий данных позволило высвободить большой объем полезного пространства. В результате отказа от локального хранения компания получит выгоду в размере 2,1 миллиона долларов.
Диагностическая информация в сфере здравоохранения занимает достаточно большой объем дискового пространства, и ее прирост все увеличивается за счет усовершенствования медицинского оборудования и методик диагностирования заболеваний. Прерывание потока обновленной информации может негативно сказаться на работоспособности медучреждения, и подобная беда могла случиться с бельгийской больницей AZ Groeninge, которой экстренно потребовалось расширение своих ленточных хранилищ после слияния ИТ-инфраструктуры с четырьмя другими учреждениями. Для выхода из ситуации был построен метрокластер на оборудовании NetApp для передачи 512 терабайт данных без прерывания работы основных узлов больницы. Данная задача была реализована с помощью технологии NetApp Swing Gear и временного хранилища для переноса уже наработанной информации, в то время как новые данные поступали напрямую. Управляла переносом система NetApp Oncommand, снабженная искусственным интеллектом, которая оптимизировала потоки данных. Работоспособность учреждения не была потеряна.
Это всего лишь пара примеров, когда технологии хранения помогают решить проблемы больших данных. Проблемы с производительностью, обеспечение надежности, миграции любого уровня, оптимизация хранения – вот неполный перечень вопросов, которые готовы решать системы нового поколения вроде NetApp StorageGRID SG, адаптированные под новый формат работы с данными и способные определить время для обеспечения комфортной работы с Big Data.
По версии IDC, к 2020 году общий объем мировых данных превысит 40 зетабайт. Для понимания подобного масштаба: 1 зетабайт примерно равен миллиарду терабайт и для размещения такого объема данных необходимо 83 миллиона дисков по 12 терабайт каждый. В «эпоху данных» крайне важно развивать инструменты для хранения информации в ногу с ростом ее объемов, иначе проблема V всегда будет стоять грозной тенью за спиной развития Big Data.
Вместо заключения
Надеюсь, у нас получилось рассказать вам, как мир IT-технологий пришел к необходимости появления технологии Big Data, и у вас сложилась ясная картина, как эти технологии работают и где применяются. Их перспективы просто огромны. Только представьте, какой прорыв можно сделать в медицине, автоматизировав разработку вакцин от новых штаммов вирусов, проводить и анализировать бесчисленное множество экспериментов по борьбе с неизлечимыми на данный момент болезнями. И это далеко не единственная научная деятельность, где технологии Big Data способны помочь совершить настоящий прорыв. Дальнейший полет фантазии мы оставим читателю. И помните, что данные – это новая нефть, а Большие Данные…
NetApp, Inc
NetApp – лидер на рынке систем хранения данных и решений для хранения, управления и анализа информации как в локальных, так и в гибридных облачных средах. Мы предоставляем компаниям возможность управлять своими данными и обмениваться ими в локальных, частных и общедоступных облаках.