Недостаточно только получить знания; надо найти им приложение. И. Гёте
По следам из хлебных крошек
На понимание технологий и подходов к хранению, обработке и анализу информации, ныне известных как Big Data, сегодня мы решили взглянуть сквозь призму времени. Возможно, кому-то данный подход покажется слегка наивным, но мы уверены: ничто не ново под луной и аналоги проблем, которые стоят перед современным человеком в данной области, можно с лёгкостью найти на всех этапах развития цивилизации, а мы, подобно Гензель и Гретель, попытаемся оставить след из хлебных крошек, который выведет нас из темного леса истории к светлым лугам познания.
Всю свою историю человечество осознанно или нет сталкивалось и решало проблемы хранения и обработки информации. Ещё 10-20 тысяч лет назад прародители современного человека использовали кости для записи остатков собранных запасов – предположительно, чтобы вести торговую активность и иметь прогнозируемый остаток на нужды собственно пропитания. Это всего лишь теория, но, если она верна – это первый пример получения и анализа информации в нашей истории.
Первые библиотеки Вавилона в 2000-х годах до нашей эры, позднее – библиотеки в Александрии – всё это пример того, как люди в тот или иной момент сталкивались с вопросами хранения большого объема информации и ее консолидации для удобства использования. Проблемы тогда, правда, сводились в основном к тому, чтобы не потерять всю накопленную мудрость при следующем вражеском набеге, как это произошло в Александрии при вторжении римлян, когда большая часть библиотеки была утрачена.
Про какой-либо серьезный анализ в привычном нам контексте в то время говорить не приходилось вплоть до середины XVII века, когда Джон Грант, известный своими работами в области демографической статистики, кроме прочего выпустил труд, описывавший теорию, в которой использование аналитики смертности позволяло предупреждать о начале эпидемии бубонной чумы.
В 1865 году профессор Ричард Миллер Девинс (Richard Millar Devens) впервые ввел в обиход термин Business Intelligence, использовав его в своей книге Cyclopedia of Commercial and Business Anecdotes, где кроме прочего рассказал Генри Фернезе, который пришёл к успеху благодаря структурированию и анализу информации о деловой активности.
С увеличением количества данных, которые люди стали использовать в различных сферах своей деятельности, возникало все больше проблем с их обработкой и анализом. Так, перед переписью 1880 года американское бюро, занимавшееся переписью населения, столкнулось с трудностью и объявило, что с современными подходами к работе с данными произвести подсчет они смогут лишь за 8 лет, а при следующей переписи в 1890 году, ввиду увеличения численности населения и постоянной миграции, дать точные результаты удастся не раньше чем через 10 лет, когда они уже полностью устареют. Получалась ситуация, когда к моменту следующего сбора данных не будут еще полностью проанализированы результаты прошлой переписи, что полностью обесценивает эту информацию и ставит само существование бюро под сомнение.
На помощь пришел инженер по имени Герман Холлерит (Herman Hollerith), который в 1881 году создал устройство (табулятор), которое, оперируя перфокартами, сокращало 10-летний труд до 3 месяцев. Воодушевленный успехом Холлерит создал компанию TMC, специализирующуюся на создании табулирующих машин. Позже ее купила компания C-T-R, которая в 1924 году была переименована в IBM.
Дальнейший рост информации и проблемы, встававшие перед нашими предшественниками, всегда сводились в равной степени к вопросам хранения и скорости обработки этих данных.
Во время Второй мировой войны необходимость в быстром анализе данных послужила созданию ряда компьютеров, позволяющих дешифровать сообщения неприятеля. Так, в 1943 году британские ученые создали машину Colossus, которая ускорила расшифровку сообщений с нескольких недель до нескольких часов. Как таковой личной памяти у «Колосса» не было, поэтому данные подавались через перфорированное колесо. Трудно представить сейчас, сколько жизней спас этот, по нашим меркам, допотопный компьютер с производительностью около 6 мегагерц и как изменился бы ход истории, если не существовало бы проблем со скоростью обработки информации.
Но скорость анализа не единственный вопрос, которым были озадачены наши предшественники в середине XX века. В 1944 году библиотекарь Фремонт Райдер (Fremont Rider) выпустил труд The Scholar and the Future of the Research Library, в котором он проанализировал, что с существующим ростом выпускаемых работ библиотеки должны удваивать свою вместительность каждые 16 лет. Это приведет к тому, что, к примеру, Йельская библиотека к 2040 году должна будет состоять из 6000 миль (около 10000 км) полок.
Дальше – больше. Начиная с 1950-х годов, наряду с все увеличивающейся потребностью в хранении и обработке информации, начался бурный рост технологий ее хранения, начали появляться центры обработки данных. Люди из разных отраслей деятельности стали приходить к пониманию, что их преимущества так или иначе будут зависеть от умения хранить и анализировать информацию, а также от скорости этого анализа и полученной от него ценностью.
С началом эры Интернета, переходом на центральные хранилища данных и с лавинообразным ростом количества веб-контента (для сравнения: в 1995 году в мире существовало 23 500 веб-сайтов, а уже через год – больше 250 000) встал вопрос поиска по многообразию существующего контента. Несмотря на существование уже нескольких созданных к тому времени поисковых систем (к слову, Yahoo не имела своей вплоть до 2002 года, а использовала сторонние разработки), первой действительно приближенной к современным была система AltaVista. Ее уникальность была в том, что она использовала лингвистический алгоритм, разбивая поисковую фразу на слова и проводя поиск по существующим индексам для ранжирования результата. За два года количество запросов в день изменилось с 300 000 до 80 миллионов.
Все, о чем мы рассказали выше, – примеры вопросов, связанных с хранением и обработкой информации. Эту цепочку можно продолжать до бесконечности, но сам термин Big Data пришёл к нам лишь на стыке тысячелетий и кроме подходов, которые были заложены в его основу, явил миру всю совокупность проблем, с которыми сталкивался человек с начала своей истории работы с информацией.
Магия литеры V
Перед тем как вплотную подойти к вопросу о Больших Данных, технологиях и областях применения, необходимо сделать ремарку и подготовить почву для обсуждения самого вопроса.
6 февраля 2001 года Дуг Лейни (Doug Laney) из Meta Group (входит в состав Gartner) издал документ, описывающий основные проблемные зоны, связанные с повышенными требованиями к центральным хранилищам данных на фоне бурного роста e-commerce, а также делающий прогноз на изменение стратегии IT-компаний в отношении подходов к построению архитектуры решений, связанных с хранением и обработкой информации.
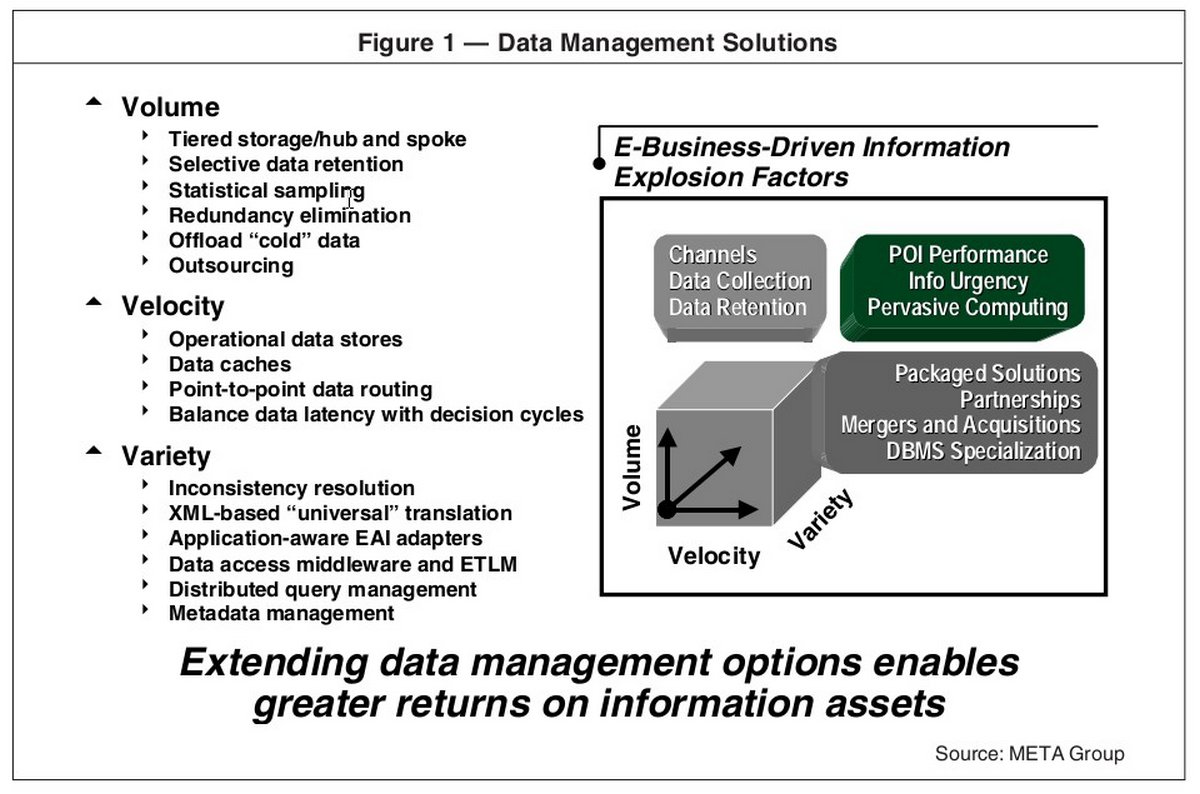
Было выделено три важнейших направления, на которых стоит сосредоточиться для решения вопросов управления данными: Volume, Velocity и Variety. Позже эти понятия стали основой для описательной модели Больших Данных под названием 3V (VVV).
Нужно учесть, что эти аспекты обсуждались без отсылки к понятию Больших Данных, концепцию которых начали применять чуть позже, но эти параметры как никакие другие описали основные принципы того, что мы с вами называем Big Data.
Volume
Важность правильного подхода к вопросам увеличения объемов данных заложена в самом понятии Big Data. Но как определить этот порог, который отличает обычное хранилище от Больших Данных? Ответ прост – никак. Big Data – это не список статичных значений, при достижении которых определяется принадлежность решения, а целый набор методик и технологий получения, хранения и обработки информации, несмотря на наличие или отсутствие в ней структурированности.
Давайте рассмотрим этот момент на примере компании Facebook, так как индустрию социальных сетей уже невозможно представить в отрыве от использования технологий Big Data. Каждые 60 секунд происходит загрузка более 130 000 фотографий и добавляется либо обновляется около 1 000 000 записей, не говоря о присоединении новых пользователей к уже существующим двум миллиардам, а также происходит коммуникация между ними и добавление медиаконтента. Большой объем данных? Несомненно. Но давайте представим, что Facebook ограничился бы исключительно получением, хранением и предоставлением этой информации по запросу. Такой подход нельзя было бы отнести к понятию Big Data. Это был бы просто огромный массив данных.
Информация сама по себе – не сила, иначе самыми могущественными людьми были бы библиотекари. Б. Стерлинг
Еще одно существенное уточнение. Когда вы оперируете такими объёмами информации, очень важно быть готовым к оперативному горизонтальному масштабированию всей совокупной системы ввиду потенциального роста входящих данных.
Давайте продолжим разбираться в этом вопросе еще глубже и перейдем к следующему параметру.
Velocity
Скорость обработки. В условиях постоянного прироста данных необходима возможность их обработки с той скоростью, которую требуют цели проекта, в контексте которого данный параметр обсуждается. Давайте представим себе, что все шахты нашей необъятной родины снабжены сотнями датчиков. Они анализируют тысячи параметров экосистемы конкретной шахты, которые затем поступают на хаб, передающий весь поток в центральный ЦОД, где выполняется обработка и анализ полученной информации.
Данные эти разнообразны и среди прочих включают в себя уровень содержания вредных веществ, сейсмические показания и прочую информацию, способную указать на вероятность обрушения, утечку газа или иные катастрофические последствия, возможные в конкретно взятой шахте. А теперь представьте себе, что поступившие данные в силу тех или иных причин были обработаны за 2 часа вместо, скажем, 10 минут и результатом обработки была информация о высоком риске обрушения, которое случилось во время анализа этой информации и поэтому превентивные меры не были приняты.
Пример, возможно, надуманный, но хорошо отражает суть Velocity, от которой зачастую зависит еще один параметр, который добавила компания IDC в эту цепочку из трех V, – Value, или ценность информации. В нашем примере эта ценность была равна нулю, так как потеряла свою актуальность раньше, чем ею смогли воспользоваться за период Validity этой информации, который говорит о сроке ее полезного действия. В другом контексте параметр Value следует рассматривать как стоимость данных, то есть помогли ли они получить готовые для анализа данные после обработки или оказались нам бесполезны.
Можно придти к выводу, что скорость обработки данных, как и хранилища, должна легко наращиваться при необходимости, что также заложено в некоторые технологии Больших Данных, позволяющие обрабатывать информацию децентрализованно. Это дает возможность масштабировать решения более гибко.
Так мы узнали еще одну сферу, где применение Big Data более чем оправданно, – это IOT, или интернет вещей, который уже давно перерос из бытовой сферы умных домов в нечто большее.
Variety
Все примеры работы с информацией из нашего исторического вступления сводились к работе с так или иначе структурированными данными. Но что делать, если информация приходит в неструктурированном виде и ее нельзя разложить «по полочкам»? Уже в 1998 году инвестиционный банк «Мерилл Линч» заявил, что до 90% всей потенциально полезной информации не структурировано.
Допустим, вы решили анализировать систему электронных сообщений в своей компании (естественно, с согласия своих работников). Данные, которые можно назвать структурированными, – это наименование отправителя, получателя, даты отправки, получения и прочая информация, которую можно явно определить в заранее согласованную ячейку базы данных. На этом этапе проблем не возникает, и если вы решили собирать информацию о количестве писем, частоте отправки или, скажем, среднем размере письма, у вас это легко получится. Но что делать с вложениями или текстом письма? Какую информацию можно получить, просто распределяя их в поля text или attaches, если, к примеру, вы хотите узнать, пишут ли ваши сотрудники стихи в переписке, используют ли корпоративную почту в личных целях? Без интеллектуального анализа данных разобраться в этом вопросе невозможно.
Кроме приведенного примера, неструктурированными можно считать любые данные, которые нельзя связать с уже имеющейся моделью. Поэтому одна из задач, которая ставится перед использованием Big Data (в большей степени, нежели хранение информации), – получая на входе большой массив разнотипных данных, оперативно выстроить между ними связи и на выходе отдать данные, доступные для структурированного или полуструктурированного анализа.
Давайте подытожим все, о чем мы сегодня поговорили, и попробуем сформулировать в двух словах, что мы знаем о Big Data.
Во-первых, не всегда большой объем данных говорит о системе, что она решает вопросы Больших Данных.
Во-вторых, важно поддерживать необходимую скорость обработки поступающих данных, иначе можно потерять их ценность и передать на дальнейший анализ уже невалидные данные или в качестве результата предоставить неактуальную информацию.
В-третьих, важно уметь находить связи между любыми данными, вне зависимости от уровня их структурированности, и уметь получать результат, который можно однозначно анализировать для решения той или иной задачи.
В-четвертых, система должна быть хорошо масштабируемой на уровне логики, иначе мы рискуем получить недостоверные данные ввиду потери одного из магических V, потери которого неизбежны при наличии бОльшего потока информации, нежели мы можем обработать.
Получается, что Big Data – это горизонтально масштабируемая система, использующая набор методик и технологий, позволяющих обрабатывать структурированную и неструктурированную информацию и строить связи, необходимые для получения однозначно интерпретируемых человеком данных, не успевших потерять актуальность, и несущая ценность преследуемых им целей.
Многие могут что-то добавить, ведь определений Big Data существует, возможно, не меньше, нежели компаний, ее использующих. Но этого определения нам будет достаточно для перехода ко второй части статьи, где мы рассмотрим примеры и области применения, а также поговорим о технологиях, которые используются в Big Data.
NetApp, Inc
NetApp – лидер на рынке систем хранения данных и решений для хранения, управления и анализа информации как в локальных, так и в гибридных облачных средах. Мы предоставляем компаниям возможность управлять своими данными и обмениваться ими в локальных, частных и общедоступных облаках.