
Прозрачность (Transparency) в контексте искусственного интеллекта означает, что все действия и решения системы можно проанализировать и понять. Это включает в себя доступность информации о том, как ИИ обрабатывает данные, какие алгоритмы используются и какие факторы влияют на его решения. Команда Стэнфордских ученых разработала «Индекс прозрачности основной модели» (Foundational Model Transparency Index, FMTI) и проверила с его помощью 10 крупнейших моделей ИИ.

Почему решили составить Индекс прозрачности моделей искусственного интеллекта
Прозрачность ИИ помогает повысить доверие к системам и позволяет регуляторам более эффективно контролировать их функционирование.
Компании, работающие в сфере ИИ, становятся все менее прозрачными, считает Риши Боммасани, руководитель Центра исследований базовых моделей (CRFM) Стэнфордского университета HAI. Например, компания OpenAI, в названии которой есть слово «открытый», четко заявила, что не будет прозрачной в отношении большинства аспектов своей флагманской модели GPT-4.
Меньшая прозрачность создает затруднения для пользователей:
- потребители не знают ограничения модели;
- ученые не уверены, могут ли опираться на модели для исследований;
- другие компании не понимают, могут ли они безопасно создавать приложения на основе коммерческих базовых моделей;
- политики не могут разрабатывать регламент для регулирования технологии.
Для оценки прозрачности Боммасани и директор CRFM Перси Лян собрали междисциплинарную команду из Стэнфорда, Массачусетского технологического института и Принстона. Они разработали систему оценок под названием Foundational Model Transparency Index (FMTI). Индекс оценивает 100 различных аспектов прозрачности, начиная с того, как компания создает модель фундамента, как она работает и как используется в дальнейшем.
Рейтинг компаний-разработчиков по Индексу прозрачности их моделей искусственного интеллекта
Исследователи оценили по 100-балльному индексу 10 крупнейших компаний, которые занимаются разработкой моделей ИИ. Ученые обнаружили, что им есть куда расти: самые высокие оценки варьируются от 47 до 54 баллов, что не вызывает особого восторга. Самая низкая оценка составляет 12 баллов.
Модель Llama 2 от Meta* получила наивысшую оценку, но это всего 54 балла из 100. Ни один из крупных разработчиков базовых моделей не приблизился к обеспечению достаточной прозрачности, что свидетельствует о фундаментальном отсутствии прозрачности в индустрии ИИ. Средний балл составляет всего 37%. Разработчики могут значительно повысить прозрачность, переняв лучшие практики у своих конкурентов.
Лидируют разработчики открытых базовых моделей. Два из трех разработчиков открытых моделей (Llama-2 от Meta* и BLOOMZ от Hugging Face) получили две высшие оценки. Оба позволяют загружать весовые коэффициенты своих моделей. Stability AI, третий разработчик open source моделей, занимает четвертое место, уступая OpenAI.
Какие показатели используют для определения уровня прозрачности модели искусственного интеллекта
Для создания индекса FMTI Боммасани и его коллеги разработали 100 различных показателей прозрачности. Эти критерии взяты из литературы по искусственному интеллекту, а также из сферы социальных сетей, где существует более развитая практика защиты прав потребителей.
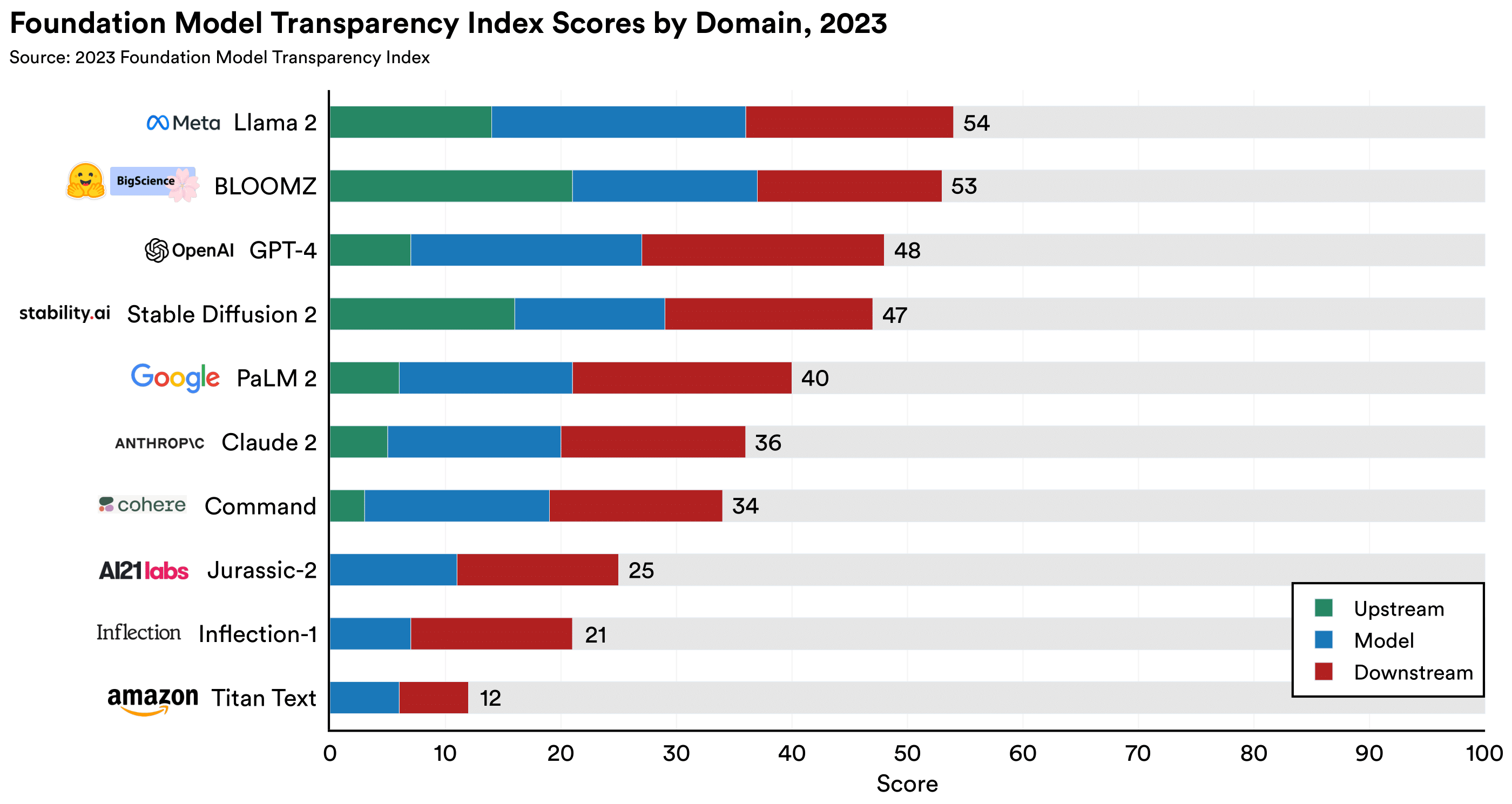
Все показатели поделены на 3 группы:
- Upstream, или как разработчики строят свои модели: информация об обучающих данных, трудозатратах на их создание и задействованных вычислительных ресурсах;
- Model, или информация о модели: ее возможности, достоверность, риски и их снижение;
- Downstream, или как модель распространяют: раскрытие политики компании в отношении распространения моделей, защиты данных пользователей и поведения моделей, а также предоставляет ли компания возможность обратной связи или возмещения ущерба пострадавшим лицам.
Помимо трех групп верхнего уровня (upstream, model и downstream), все оценки объединены в 13 категорий. Благодаря этому анализ получился более глубоким и детальным.
Данные (Data), трудозатраты (labor) и вычисления (compute ) — «слепые зоны» для разработчиков, поэтому по этим ресурсам прозрачность низкая. Сумма баллов по этим показателям у всех разработчиков составляет всего 20%, 17% и 17% от общего количества.
Зато более высокая прозрачность в вопросах защиты данных пользователей и базовой функциональности своей модели. Разработчики получили высокие баллы по показателям, связанным с защитой пользовательских данных (67%), основными сведениями о том, как разрабатываются их базовые модели (63%), возможностями их моделей (62%) и их ограничениями (60%). Это демонстрирует прозрачность разработчиков в отношении того, как они обрабатывают пользовательские данные и какова базовая функциональность их продуктов.
Однако даже в тех областях, где разработчики наиболее прозрачны, есть возможности для совершенствования. Ни одна компания не предоставляет информацию о процессе предоставления доступа к данным об использовании модели. Лишь немногие разработчики демонстрируют ограничения своих моделей или предлагают третьим сторонам оценить их возможности. Только три разработчика раскрывают компоненты модели и только два — размер модели.
Почему балл начисляют, даже если компания не раскрывает данные
«Мы стремимся создать индекс, в котором большинство показателей не противоречат интересам конкуренции. Раскрытие информации не должно также способствовать злоупотреблениям со стороны других участников экосистемы», — говорит Боммасани.
Действительно, по некоторым показателям балл начисляется, если компания не раскрывает запрашиваемую информацию, но при этом обосновывает причины умалчивания.
Кроме того, Индекс намеренно не ориентирован на оценку корпоративной ответственности. Если компания раскрывает информацию о том, что обучение ее моделей требует много энергии, что она не платит своим работникам прожиточный минимум или что ее пользователи наносят вред, она все равно получит балл FMTI за такую открытость.
Хотя цель Индекса FMTI — более ответственное поведение компаний, все же прозрачность — это первый шаг в этом направлении, считает разработчики системы оценки. Раскрывая все факты, FMTI создает условия, которые позволят регулятору или законодателю решить, что необходимо изменить.
Где брали информацию о моделях искусственного интеллекта
Для составления рейтинга лучших создателей ИИ-моделей исследовательская группа использовала структурированный протокол поиска для сбора общедоступной информации. Это включало изучение веб-сайтов компаний, а также выполнение ряда воспроизводимых поисковых запросов в Google по каждой компании.
«Мы считаем, что если в ходе такого тщательного процесса не удалось найти информацию о каком-либо показателе, значит, компания не была прозрачной в этом вопросе», — говорит Кевин Клайман, студент магистратуры Стэнфордского университета по международной политике и один из ведущих соавторов исследования.
После того как команда подготовила первый проект рейтинга FMTI, она предоставила компаниям возможность ответить на вопросы. Затем группа рассмотрела информацию от представителей компаний и внесла необходимые изменения.
Есть еще один важный момент: ни одна компания не предоставляет информацию о том, сколько пользователей зависит от ее модели, статистику по географическим регионам или секторам рынка, в которых используется ее модель. Большинство компаний также не раскрывают информацию о том, в какой степени в качестве обучающих данных используются материалы, защищенные авторским правом. Не раскрывают компании и информацию о своей трудовой практике, которая может быть весьма проблематичной.
«На наш взгляд, компаниям следует начать делиться с общественностью подобной важной информацией о своих технологиях», — говорит Кевин Клайман.
Почему важна прозрачность моделей искусственного интеллекта
Отсутствие прозрачности — уже давно проблема для потребителей цифровых технологий: обманчивая реклама и ценообразование в Интернете, неясная практика оплаты труда, схемы, которые склоняют людей к неосознанным покупкам. Сюда стоит добавить множество проблем с модерацией контента, что привело к появлению огромной экосистемы дезинформации в социальных сетях.
Кроме того, прозрачность коммерческих базовых ИИ-моделей важна для продвижения инициатив в области ИИ. Пользователи в промышленности и научных кругах должны иметь доступ к информации, которая необходима для работы с этими моделями. Это поможет принимать обоснованные решения.
«По мере того как технологии ИИ быстро развиваются и стремительно внедряются в различных отраслях, журналистам и ученым особенно важно понимать их конструкцию и, в частности, компоненты или данные, которые их питают», — считает Шейна Лонгпре, кандидата наук из Массачусетского технологического института.
Meta* — экстремистская и запрещенная в РФ организация.