Деперсонализация кажется простой задачей, пока не сталкиваешься с реальностью. На практике это полноценный инженерный вызов, сочетающий профилирование, проверку бизнес-логики, оптимизацию и работу с нетривиальными особенностями инфраструктуры. В статье Петр Мельченко, лид команды разработки в «Перфоманс Лаб», и Василий Жидков, продакт-менеджер DataSan, разбирают технические сложности, через которые проходят команды, когда пытаются организовать обезличивание в больших системах, — и решения, позволяющие пройти этот путь.

С 30 ноября 2024 года вступили в силу важные изменения в законодательстве о защите данных. Теперь за нарушения, связанные с обработкой и защитой персональных данных, появилась уголовная ответственность для сотрудников, отвечающих за информационную безопасность и работу с данными.
Помимо этого, введены оборотные штрафы: за повторные нарушения компания может заплатить до 3% от годового оборота. Суммы ощутимые, особенно для бизнеса, который работает с большими объемами пользовательских данных.
Когда мы обсуждаем нововведения с инженерами, быстро становится ясно: один штраф стоит дороже, чем внедрение нормального процесса обезличивания. И уж точно не стоит того, чтобы рисковать уголовной ответственностью. Поэтому сегодня вопрос «нужно ли обезличивать?» уже не стоит — стоит вопрос, как сделать это эффективно и безопасно.
Как правильно выделить и обработать персональные данные
В процессе обезличивания мы опираемся на два ключевых понятия: профилирование и деперсонализация. Профилирование — это поиск полей, содержащих персональную информацию. Искать можно не только ПДн, например, нас в разных проектах просили находить размер каски, обуви и другие специфичные параметры — все это решалось без проблем.
В свою очередь, деперсонализация (обезличивание) — это изменение найденных данных таким образом, чтобы при возможной утечке они не представляли ценности для злоумышленников и не могли быть использованы против пользователя или компании. Неважно, относятся ли данные к категории персональных или к любому другому чувствительному типу — принцип один и тот же.
На первый взгляд кажется, что определить персональные данные достаточно просто: фамилия, имя, отчество, номер телефона, паспорт, ИНН, СНИЛС — все это очевидные категории. Но на практике возникает вопрос: «Как отличить, например, ИНН от любого произвольного набора цифр?». Чтобы минимизировать ложные срабатывания, мы добавляем дополнительные проверки:
- для СНИЛС используем проверку контрольной суммы;
- для паспортных данных анализируем первые четыре цифры, чтобы убедиться; что это действительно паспорт, а не случайная последовательность.
Отдельная важная задача — сохранение консистентности. Когда мы обезличиваем данные из разных баз, одно и то же имя или номер телефона должны превращаться в одинаковые значения. Это критично для последующего анализа и работы с наборами данных, чтобы обезличенные данные оставались полезными и связными.
Еще один частый сценарий — географически распределенные дата-центры. Между ними может не быть связи вовсе, но при этом важно, чтобы данные в разных хранилищах обезличивались одинаково. Мы решаем и такую задачу: две независимые базы должны выдавать совпадающие обезличенные значения для одних и тех же исходных данных.
Есть и другая особенность, с которой сталкиваются команды тестирования. Если на вход тестам вместо фамилии и имени приходит случайный набор букв, такие значения легко ломают логику сценариев. Поэтому мы научились преобразовывать реальные данные в корректные, естественно выглядящие аналоги: превращать Васю Петрова в Петра Иванова, генерировать валидные номера телефонов и паспортов, корректно подбирать даты рождения.
Бывают и более специфичные запросы. Например, страховая компания просила сохранить информацию о том, что клиент старше 18 лет, но при этом «сдвигать» дату рождения так, чтобы она обязательно попадала в первую или вторую половину месяца — потому что на этом основана внутренняя логика расчета коэффициентов. Таких кейсов у нас накопилось много, и каждый требовал отдельного подхода.
В итоге сформировалась большая библиотека способов корректного и устойчивого обезличивания данных — и это, как оказалось, куда сложнее, чем кажется на первый взгляд.
Технические сложности профилирования
Первый шаг — понять, с какими видами данных вы работаете. Типовой список включает ПДн физических лиц включает:
- ФИО;
- адрес;
- телефонный номер;
- паспортные данные;
- СНИЛС;
- ОГРН;
- ИНН;
- номер счетов / банковских карт.
Однако в зависимости от домена персональные данные могут относиться не только к физическим лицам: могут быть задействованы и юридические лица, и другие типы сущностей. На этом этапе важно четко зафиксировать, что именно считается чувствительными данными в вашем контуре.
Даже разобравшись с тем, что искать, нужно понять, как это искать. Мы выделяем три основных метода: метаданные, словари и регулярные выражения. У вас могут появиться дополнительные методы, но эти три — основа.
Чтобы методы профилирования работали корректно, требуется предварительно собрать и подготовить данные. Это включает:
- наполнение словарей фамилиями, именами и другими возможными значениями;
- создание и отладку регулярных выражений для структурированных типов данных (например, ИНН, СНИЛС и т. д.);
- поддержку и обновление этих словарей и шаблонов по мере появления новых форматов и правил.
Это трудоемкий этап, без которого невозможно добиться точного распознавания чувствительных данных. Когда данные готовы, нужно собрать движок, который умеет все это применять. Если база данных большая, движок придется долго оптимизировать, чтобы он справлялся с нагрузкой, корректно масштабировался и при этом оставался достаточно быстрым.
Даже если профилирование прошло успешно и у вас есть готовый профиль данных, работа на этом не заканчивается. Базы со временем обновляются, например, появляются новые поля и таблицы. Значит, профилирование нужно выполнять повторно — хотя бы по дельте изменений. Это также должно быть заложено в архитектуру движка: инструмент обязан уметь находить новые сущности без полного пересканирования всего хранилища.
Технические сложности деперсонализации
Уникальные сущности и «забытые» места хранения данных
Может показаться, что достаточно обезличить основные таблицы — и работа сделана. На практике это далеко не так. Важно отметить, что пример далее приведен на базе Oracle, и часть подобных проблем специфична именно для этой СУБД. В других системах хранения данные сложности могут проявляться иначе или не встречаться вовсе.
Material View
Физический объект базы данных, который содержит результат выполнения запроса. Материальные представления могут содержать слепки данных, которые не обновились после обезличивания основной таблицы. Поэтому они должны входить в общий контур обработки.
Material View Log
Рядом с ними в Oracle существует еще одна специфичная сущность — Material View Log. Это вспомогательный физический объект для оптимизации работы с материальными представлениями (позволяет выполнять fast refresh вместо complete refresh). С точки зрения обезличивания не вызывает дополнительных задач, но становится источником серьезных проблем при параллельной обработке данных. В процессе вы рискуете получить взаимные блокировки и остановить весь пайплайн.
Отключить Material View Log нельзя — его приходится удалять и затем восстанавливать. Это нужно учитывать и вписывать в общий процесс обработки данных.
Constraints
Правила, которые добавляются при изменении/добавлении данных в таблицу. Даже если вы умеете корректно работать с нужными полями, всегда существуют ограничения в базе. Например:
- дата закрытия договора не может быть раньше даты открытия;
- связанные значения должны оставаться согласованными.
Все такие ограничения тоже нужно профилировать и учитывать при обезличивании. Иначе результат будет некорректным, а база — потенциально сломанной.
Проблемы при пересоздании базы данных
JDK и Java-объекты
В ряде кейсов при восстановлении базы мы сталкивались с тем, что в Oracle:
- отсутствует возможность компилировать Java source;
- версия JDK отличается от ходовой.
В результате часть логики, завязанной на Java внутри БД, просто перестает работать. Исправляется это довольно приземленно — переустановкой JDK и приведением версии к нужной.
Индексы в невалидном состоянии
При копировании часть индексов оказывается сломанной, что приводит к остановкам при обновлении таблиц.
Чаще всего это всплывает не на «боевых» таблицах, а на:
- архивных таблицах;
- пользовательских слепках/копиях, которые когда-то сделали «на всякий случай» и про них забыли.
Один из обязательных шагов — научиться обнаруживать и корректно обрабатывать такие индексы: либо чинить, либо переcоздавать, либо исключать эти объекты из обработки по согласованным правилам. Иначе процесс обезличивания будет регулярно ломаться на забытых и «заброшенных» участках базы.
Проблемы с настройками баз данных и таблиц
Низкое значение Initrans
Один из характерных примеров — параметр INITRANS в Oracle. Он отвечает за количество DML-запросов, которые могут выполняться параллельно на записях внутри блока данных.
Когда таблица большая и активно обновлялась, ее блоки могут иметь слишком низкое значение INITRANS. В результате при массовом обновлении данных мы параллельно обращаемся в разные блоки и начинаем блокировать сами себя, создавая задержки и замедляя процесс обезличивания.
Исправить ситуацию простым изменением настройки нельзя: для применения потребуется MOVE, а это уже отдельная трудоемкая операция, потенциально влияющая на структуру таблицы. Поэтому на практике проблему приходится решать ручной обработкой взаимных блокировок.
Ограничение свободного места в tablespace
Массовое обновление занимает дополнительное пространство, и если его мало, процесс может просто не завершиться. Это тоже нужно учитывать заранее.
Валидация отдельных сущностей
Отдельная группа проблем — корректность данных после обезличивания.
Во-первых, это техническая валидация. Например:
- прохождение котрольных суммы (СНИЛС, ИНН и т. д.);
- корректность формата имени;
- структуры номера документа.
Если такие проверки не пройдены, приложение может отказать на ровном месте, потому что формат данных перестанет соответствовать ожиданиям.
Во-вторых, есть валидация сохранения бизнес-логики, которую нельзя игнорировать. Например:
- дата закрытия договора не может быть раньше даты открытия;
- дата рождения должна соответствовать паспортным данным;
- связанные сущности должны оставаться согласованными.
Все эти правила должны учитываться прямо в методах обезличивания, иначе база после обработки окажется в неконсистентном состоянии и вызовет дефекты в потребляющих системах.
Оптимизация алгоритмов обезличивания
Все перечисленные сложности приводят к тому, что даже если вы собрали свой рабочий движок, на больших базах данных проблемы с оптимизацией все равно рано или поздно появятся.
Распараллеливание процессов
Для крупных БД необходимо уметь распараллеливать обработку. Если ваше решение основано, например, на stored procedures или схожем подходе, нативной поддержки параллелизма там обычно нет.
Значит, придется придумывать дополнительный механизм:
- запускать отдельные jobs;
- управлять ими через планировщики;
- контролировать распределение нагрузки.
И это само по себе становится отдельной инженерной задачей.
Оптимизация алгоритмов
Даже если алгоритмы работают корректно, на практике почти всегда оказывается, что скорость обработки оставляет желать лучшего. Массовые обновления, большие объемы данных, сложные проверки и валидации — все это требует оптимизации.
Иногда приходится пересматривать часть логики, перерабатывать методы или менять подход к обработке данных, чтобы уложиться в адекватное время выполнения.
Пример решения с Oracle
Изначально у нас был простой и понятный конвейер. Один общий планировщик проходил по списку таблиц, которые нужно обезличить.
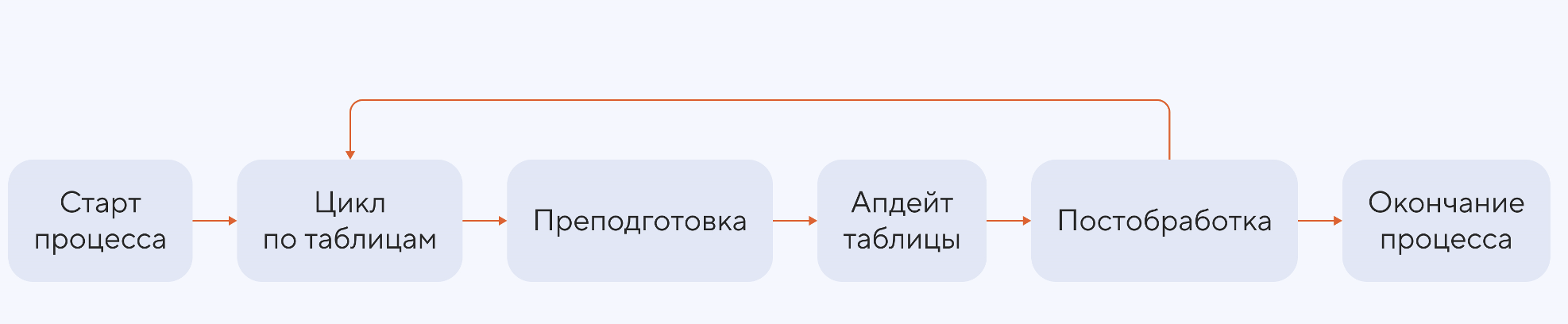
Для каждой таблицы мы отключали индексы и триггеры, запускали через планировщик набор работ, которые выполняли обновления, и по завершении возвращали индексы и триггеры обратно. Так мы проходили все таблицы по очереди, но когда мы обезличивали данные в одном из банков, оказалось, что такой процесс перестал справляться с нагрузкой.
На графике утилизации CPU выше видно множество «пустых» участков — ресурсы простаивали, а значит, мы теряли время. Для больших объемов данных это неприемлемо. Мы полностью пересобрали процесс, чтобы устранить простои и максимально загрузить доступные ресурсы.

Теперь пайплайн выглядит так:
- первый планировщик проходит таблицы в прямом порядке и обрабатывает крупные таблицы;
- второй планировщик идет навстречу первому, но работает с мелкими таблицами — в обратном порядке;
- третий планировщик занимается включением индексов и триггеров, потому что это длительная операция, которая не должна блокировать основной поток обработки.
На выходе — новый график утилизации CPU, где «провалов» практически нет. Все ресурсы загружены равномерно, а процесс обезличивания работает заметно быстрее.
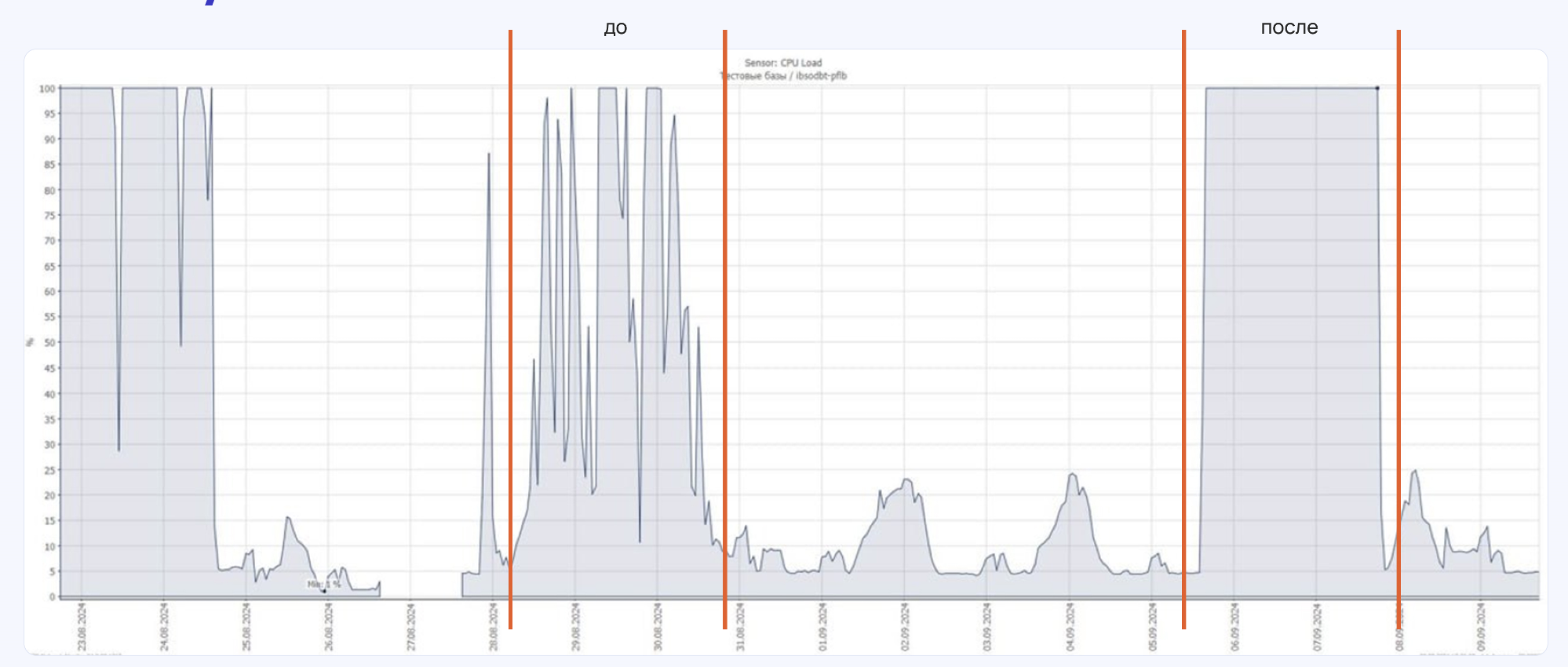
Для нас это был важный шаг вперед: более гибкая схема распараллеливания дала ту производительность, которой мы не могли добиться предыдущим подходом.
Дальнейшие планы по продукту DataSan
После нескольких лет работы над ядром мы пришли к тому, что пора развивать пользовательский интерфейс. Это одно из наших ближайших направлений — сделать работу с инструментом более удобной и прозрачной.
Параллельно мы развиваем новый модуль усечения данных. На Oracle он уже доступен в стабильной поставке. Этот модуль позволяет значительно сокращать время обезличивания в тех случаях, когда нет необходимости обрабатывать всю базу целиком.
Усечение можно выполнять по разным параметрам — не только по дате, но и, например, по фамилиям или сериям паспортов. Мы планируем расширить поддержку и вынести модуль за пределы Oracle, чтобы он был доступен в других СУБД.
Разумеется, продолжаем развивать и профилирование — это один из ключевых и наиболее трудоемких этапов, который требует постоянного улучшения.