
ИИ призван заменить тысячи рабочих мест не только в разработке программного обеспечения, но и в различных областях, таких как журналистика, творческая работа, взаимодействие с клиентами и другие. Это та же мантра, которую мы слышали обо всех предыдущих технологических инновациях: «Компьютер полностью заменит человека».
В статье сосредоточимся на реальном рассмотрении того, что произойдет, если большие языковые модели (LLM) полностью заменят человеческую работу.

Как обучаются LLM
С точки зрения простого пользователя, языковые модели на основе машинного обучения для создания текста и изображений можно сравнить с мясорубкой, которая преобразует существующие данные и материалы в новый контент. Процесс обработки данных включает в себя многократное смешение и комбинирование исходных компонентов для создания нового результата.
Если искусственный интеллект будет обучаться на небольших объемах данных без доступа к исходной информации, это может привести к потере частей первоначальных данных. В таком случае LLM не способен использовать контекст из прошлого опыта. Например, известные нейросети, такие как Copilot и GPT, не смогли создать базовый код для операционных систем Macintosh конца 80-90-х годов из-за отсутствия исторической информации в обучающих данных.
Обучение LLM основано на относительно актуальных данных и тенденциях, что подчеркивает сложность задачи обучения как на маленьких, так и на больших объемах данных. Поскольку LLM стремятся к обобщению доступной информации, они могут испытывать затруднения в решении конкретных проблем. Чем более узкоспециализированной является задача, тем более детальным и конкретным должен быть входной набор данных (промт).
LLM неспособны оценить собственную работу
При создании работы люди иногда могут переоценить свои достижения и подвергнуть свои творения проверке на правдоподобие. Лингвистические модели на основе машинного обучения пытаются эмулировать этот процесс, рекурсивно перерабатывая свои собственные результаты.
Однако у ИИ есть ограничения в оценке, связанные с количеством итераций, которые он может выполнить. В отличие от человека, который может потратить разное количество времени на повторные итерации для достижения желаемого результата, LLM ограничивается определенным числом шагов и, следовательно, временем.
Эрику Артуру Блэру, более известному как «Джордж Оруэлл», потребовалось целых три года, чтобы завершить свою знаменитую книгу «1984». Он проживал на уединенном острове Юра, находящемся на западе Шотландии, где посвятил все это время работе над произведением, доводя его до состояния, которое он считал достойным публикации.
В отличие от творцов, подобных Джорджу Оруэллу, лингвистические модели на основе машинного обучения не продолжают работу до достижения оптимального результата, а завершают свою деятельность по достижении предельного количества циклов обработки. Это можно сравнить с немотивированным работником, который заканчивает свою смену в определенное время, независимо от качества работы.

При применении качественных фильтров к реализации LLM осуществляется проверка как запросов, так и выходных данных на наличие нежелательного контента. Запросы, явно указывающие на неподходящий контент, могут быть легко отфильтрованы. Однако, при использовании специализированных LLM для проверки соответствия подсказок, существуют методы использования языка, которые могут обойти эти проверки и обмануть ИИ, заставив его создавать нежелательный контент.
Для явного изображения человеческого тела это достигается путем использования специализированных медицинских терминов из анатомии. В программном обеспечении аналогичный результат может быть достигнут путем запроса кода, который неизбежно предоставляет учетные данные.
У LLM отсутствуют дифференциация и контекст
Для предотвращения утечки нежелательного контента, который не должен генерировать ИИ, используются выходные фильтры. LLM может создать выходные данные, например, учетные данные в коде или явные изображения, но конечный выходной фильтр обнаружит эту информацию и удалит результат или определенную часть данных. Такое поведение наблюдается при использовании DALL-E через Microsoft Copilot, что приводит к задержке и генерации менее четырех изображений по умолчанию.
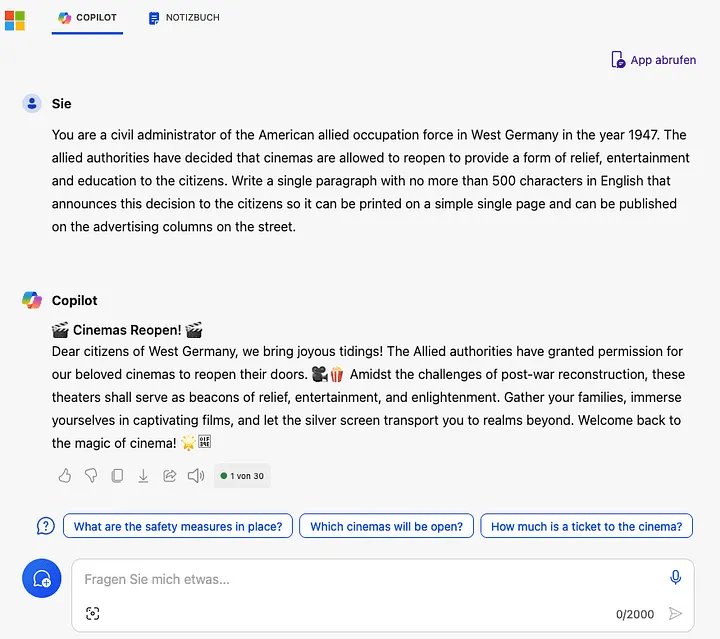
При использовании медицинских терминов в обучающих данных модель часто включает множество анатомических деталей, что приводит к созданию контента, который может быть считан неподходящим выходным фильтром. Модель не всегда способна различить простое анатомическое изображение пальца ноги от явного отображения частей тела.
При запросе «создайте изображение женщины лет 40, идущей по лесу босиком» LLM создаст три изображения, одно из которых будет удалено выходным фильтром. Изменение запроса на «создайте изображение женщины за 40, идущей по пляжу босиком жарким летним днем» может привести к отфильтровке всех результатов или к получению только одного изображения. Учитывая усилия людей, пытающихся обойти фильтры и заставить LLM создавать нежелательный контент, правила фильтрации очень строги и часто приводят к ложноположительным результатам.

Интенсивная фильтрация с высоким уровнем ложных срабатываний приводит к тому, что LLM ограничены в выдаче выходных данных для конкретных приложений, таких как анатомия или история. Это неизбежно влечет за собой ограничения и в других областях применения.
LLM создают блокады на основе предубеждений
Из-за культурных предубеждений, которые существуют в LLM, используемых североамериканскими компаниями, модели могут легко создавать изображения с различными видами оружия, но отказываются показывать сцены людей, стреляющих из пистолета или любые другие демонстрации большого количества боеприпасов. Все еще существуют способы обойти входные и выходные фильтры LLM, используя подсказки, которые не обнаруживаются фильтром.

Фильтры в LLM заданы программно и, как правило, их сложно обойти. Эта культурная предвзятость часто становится основой многих обсуждений в области искусственного интеллекта и больших языковых моделей. Хотя смещения фильтров могут быть внесены операторами, у самой модели LLM также возникает собственное смещение. При наличии обучающих данных, содержащих чрезмерно популярную информацию, LLM будет предпочитать наиболее распространенные варианты.
Хотя оператор может преодолеть смещение фильтра, убрав ограничения или вовсе удалив фильтры, естественное смещение сложнее преодолеть. Распространенные методы включают в себя рандомизацию, продвижение новых идей, временные модели декарирования и многие другие подходы. Они, в основном, снижают эффект смещения, но не устраняют его полностью.
LLM полагаются на статус-кво
Искусственный интеллект перерабатывает наиболее распространенные знания в новый языковой контент, что может способствовать поддержанию статус-кво вместо постоянного вызова на инновации. Кроме того, ИИ зависит от людей для внесения новшеств, поскольку человек должен предоставлять обучающие данные с новыми идеями, которые LLM может интегрировать в свою работу. Важно, чтобы человек контролировал этот процесс, чтобы избежать естественного предвзятого отношения к существующему положению вещей и побудить LLM принимать более современную информацию.
Представьте себе искусственный интеллект, который разрабатывает программное обеспечение, пишет документацию и обеспечивает поддержку клиентов. Хотя LLM может включать отзывы клиентов для улучшения программного обеспечения, он не способен самостоятельно придумывать новые идеи или использовать креативность для разработки новых методов или подходов.

Чем ИИ будет отличаться от человека
Если LLM будет создавать программное обеспечение самостоятельно, это может улучшить его для пользователя, но не приведет к техническим инновациям и не позволит преодолеть границы существующих технологий.
Более того, вероятно, искусственный интеллект, неспособный логически осмыслить систему в целом, может привести к искажению функциональности или даже к хаосу после нескольких итераций изменений. Учитывая, что большинство программных продуктов требуют большего количества изменений, чем может обработать человек, LLM должен постоянно работать, чтобы оставаться впереди человека.
Во что обойдется замена инженера-программиста на ИИ
С точки зрения затрат, LLM, вероятно, должны обработать сотни тысяч строк инструкций, кода и схем для выдачи точных результатов. По текущим оценкам, почасовая оплата LLM, заменяющей инженера-программиста, составляет около $90-120 в час, что в результате при круглосуточной работе влечет затраты в $64 800 в месяц.
Для того чтобы замена инженера-программиста ИИ была экономически целесообразной, его стоимость должна снизиться более чем на 90%. Это означало бы, что стоимость LLM должна составлять примерно $5000-6000 в месяц, включая эксплуатационные расходы и инфраструктуру DevOps. Однако текущее качество создаваемого LLM кода оставляет желать лучшего.
Все коммерческие ИИ предупреждают разработчиков программного обеспечения о возможных проблемах с безопасностью и качеством созданного кода. LLM пока не способны гарантировать безопасность и качество кода, и часто не справляются даже с простейшими задачами.
С развитием инноваций в области микросхем, оптимизированных для ИИ, LLM могут стать более эффективными и быстрыми. Однако до сих пор не доказано, что они могут быть более прибыльными, чем человек.
Чат-боты по обслуживанию клиентов также вызывают сомнения
Один из наиболее распространенных способов использования искусственного интеллекта — это чат-боты для обслуживания клиентов, которые заменяют менеджеров. Поскольку это новое явление и немногие нетехнологичные компании проводят среднесрочные или долгосрочные испытания, мы еще не знаем всех возможных проблем и того, как естественное смещение может повлиять на способность чат-ботов предоставлять современные решения.
Искусственный интеллект, используемый для обслуживания клиентов, обучен сохранять статус-кво. Это означает, что им требуется перезагрузка при серьезных изменениях в бизнес-процессах, а также значительное повышение квалификации. Пример ошибки чат-бота Air Canada показывает, насколько далеко может зайти LLM в рабочей среде.
Air Canada должна соблюдать политику возврата средств, выдуманную чат-ботом
Разрешение дилеммы: LLM зависят от людей
Предприятия стремятся сократить расходы на рабочую силу с помощью ИИ, в то время как профсоюзы борются за сохранение рабочих мест для своих членов. Однако реальность часто оказывается где-то посередине. Логические ограничения искусственного интеллекта означают, что он не может функционировать без надзора и, следовательно, маловероятно, что сможет полностью заменить человека.
LLM представляют собой фантастическое изобретение, и их важность и потенциал инноваций в бизнесе не следует недооценивать. Они могут повысить производительность, автоматизируя тяжелую и утомительную работу. Это значительное улучшение для общества и экономики.
Искусственный интеллект ускоряет процессы, такие как написание стандартного кода, отправка электронных писем, общение и поиск информации. LLM представляют собой следующий этап развития программного обеспечения и заслуживают внимания, которое им уделяется в настоящее время.
Однако чат-боты не способны полностью заменить людей. Они могут выполнить определенные задачи, но не обладают креативностью и логикой человека. Также существуют специфические задачи обучения, которые до сих пор остаются нерешенными.
Хотя LLM будут развиваться, текущий подход к их внедрению делает их ограниченными с точки зрения логических возможностей. Поэтому разрешение дилеммы искусственного интеллекта может заключаться в осознании важности человеческого фактора.