
«Окей, Гугл», «Привет, Алиса» — человек все больше стремимся говорить с компьютером на том языке, который понятен ему. Рассказываем о том, как компьютер учит языки людей и о самых трендовых технологиях в этом направлении вместе с экспертом в области компьютерной лингвистики Борисом Валерьевичем Ореховым, кандидатом филологических наук, доцентом Школы лингвистики НИУ ВШЭ.

Машинный перевод
В 1950-х годах ученые обещали, что лет через пять потребность в людях-переводчиках полностью отпадет, потому что их заменят компьютеры.
Но до сих пор даже самые популярные онлайн-переводчики не могут конкурировать по качеству перевода с живыми специалистами. Зато они обыгрывают их в скорости и охвате – так, по статистике Google, приуроченной к десятилетию Google Translate, сервисом пользуется полмиллиарда человек. Кроме того, машинный перевод доступен бесплатно и поддерживает крупнейшие языки мира.
Что до качества перевода, то оно растет постепенно, но ощутимо. Вспомните легендарный переводчик PROMT и первые переводы от Google и Яндекс и сравните их с теми текстами, которые мы получаем сейчас.
Интересно, что последние десять лет ни переводчики, ни лингвисты не имеют к машинному переводу никакого отношения.

Борис Орехов рассказывает: «С пятидесятых годов прошлого века лингвисты создавали словари, расширяли грамматики, создавали алгоритмы перевода. Однако серьезных результатов удалось добиться только с помощью нейросетей. Им не требуются ни словари, ни грамматики – только живые данные, большие объемы текстов».
Нейронная сеть работает с массивами данных и улавливает в них закономерности. Например, она может анализировать последовательность букв и на ее основании выстраивать закономерности, переводить слова, которые не встречались в тренировочных данных, неологизмы.
Правда, иногда это приводит к забавным ситуациям.
Так, в 2017 году при переводе с английского на французский фразы «I am a flat earther» («Я сторонник теории плоской земли») получалось «Je suis fou» («Я сумасшедший»). Ошибку заметили и быстро убрали.
А вот на другую ошибку можно посмотреть и сейчас. Просто выберите в Google Translate перевод с монгольского на русский и напишите что-то вроде: «ааааааа оооооо уууууу». Результат вас удивит.
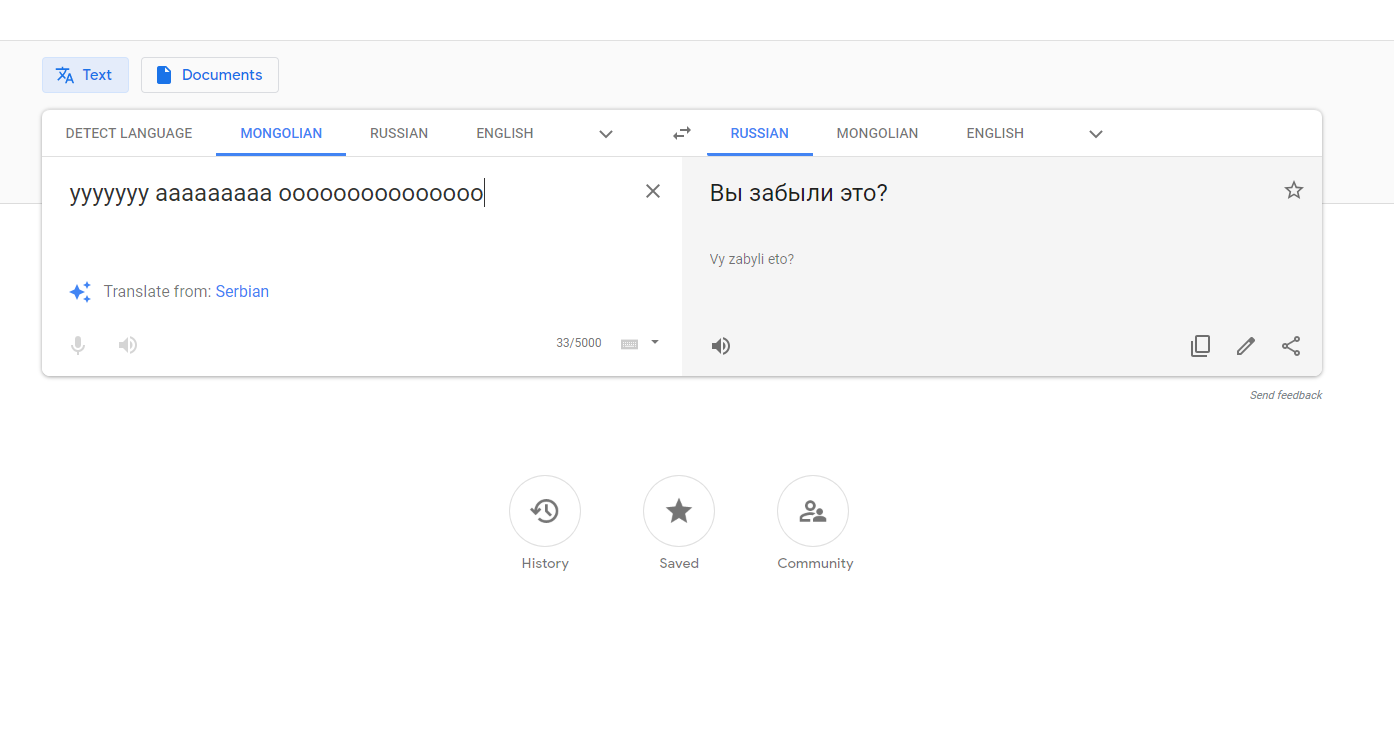
Интернет-медиа Vice.com, заметив очередную ошибку такого рода (при переводе с сомалийского на английский сочетаний типа «ag ag» сервис выдавал цитаты из Библии), обратился в Google за разъяснениями. Представители компании ответили: «Google Translate учится на примерах переводов в интернете <…> и так работает функция ввода бессмыслицы в систему: она генерирует новую бессмыслицу».
Проблемы
У машинного перевода сейчас две ключевые проблемы: это так называемые «грязные» данные и нехватка материалов.
Грязные данные возникают, когда нейросеть сопоставляет одинаковые по содержанию тексты, но не видит очевидных смысловых различий между ними: например, в тексте описаний товаров на английском все цены будут указаны в рублях, а на английском – в долларах. Поэтому нейросеть может запомнить эту параллель и переводить «рубль» как «dollar». Решение этой проблемы – дополнительное обучение нейросети и подсказки пользователей.
Что касается нехватки материалов, то эта проблема характерна для редких языков, имеющих мало письменных источников. Для перевода требуется два параллельных корпуса текстов, и если их недостаточно, то нейросеть не может обучиться. В этом случае помогает сопоставление близких языков.
Разработчик из команды машинного перевода «Яндекса» Антон Дворкович в своей статье поясняет: «Если понять, из чего состоит язык, и правильно определить нужные кусочки такого языкового конструктора, можно научиться переводить даже с вымышленных языков, в которых не так много описанных автором слов, но мы при этом можем предположить, как новые слова могли бы выглядеть. По этой же логике «Яндекс» научил свой переводчик работать с эльфийским языком».
Информационный поиск
Поисковики тоже умнеют с каждым днем – понимает не только прямые запросы, но и анализирует контекст, выдает статьи, подходящие по смыслу, но далеко не всегда содержащие слова из запроса.
Реализовать такой поиск стало возможно с развитием векторной (или дистрибутивной) семантики. Текст выстраивается в виде вектора (например, можно задать вектор каждому слову), а компьютер выполняет с ними математические преобразования.
Например, если из вектора «Москва» вычесть вектор «Россия» и прибавить вектор «Франция», получится «Париж».
Сопоставляя вектора и их значения, компьютер определяет близкие по семантике слова, причем они далеко не всегда должны быть синонимами. Так, семантически будут близкими слова «холодный» и «горячий» — то, что может быть холодным, также может быть и горячим, поэтому поисковик выдаст страницы с этими контекстами по запросу, содержащему любое из двух слов.
Применение векторной семантики очень широко: не только поиск, но и кластеризация текстов. Допустим, именно таким образом новостные агрегаторы объединяют тексты в общие темы: заголовки могут содержать разные тексты, но машина понимает, что все они близки по содержанию.

{kind=link}
Еще одна технология, которая позволяет поисковикам быть такими удобными, это выделение ключевых слов. Благодаря нему компьютер понимает, как ранжировать выдачу, что именно показывать в сниппете, определяет, о чем именно в тексте идет речь.
Голосовые ассистенты
Чат-боты и голосовые ассистенты работают тоже на тексте. Он интерпретируется и звучит за счет голосовых модулей, но в основе – это именно текст, который выучивается и обрабатывается тоже с помощью нейронных сетей.
По сути, модули этих нейросетей похожи на те, которые используются для машинного перевода: отличие в том, что используются корпуса данных не на разных языках, а на одном. В некотором роде, нейронная сеть тоже осуществляет перевод, но в качестве исходного текста выступает вопрос. А в качестве результата – ответ.

Борис Орехов: «Главная проблема голосовых ассистентов на сегодняшний день в том, что нейронные сети не умеют запоминать контекст. Допустим, когда вы ведете с голосовым помощником диалог, он не помнит, что отвечал вам три реплики назад. Человек постоянно оптимизирует речь, отсылает собеседника к уже сказанному с помощью местоимений: не повторяет каждый раз фамилию, имя и отчество, а говорит: «он» или «она». Живой собеседник контекст запоминает, а нейронная сеть – нет. Ей нельзя сказать: «А вот помнишь, мы полчаса назад обсуждали»… Она не помнит. Поэтому для действительно живого голосового ассистента требуется не только нейронная сеть, но и какие-то другие модули. Пока эта проблема не решена».
КСТАТИ
Первый чат-бот по имени Elize появился еще в 1966 году и работал с диалогами, полностью прописанными вручную. Ее создатель Джозеф Вейценбаум наделил ее умением имитировать прием у психотерапевта и использовать технику активного слушанья, выделяя главное в каждом вопросе. Если Elize не находила в своей базе подходящего ответа, она говорила: «Понятно».
По такому же принципу – с большой базой готовых диалогов – до сих пор работают чат-боты с небольшим функционалом, например, виртуальные консультанты на сайтах.
Цифровой поэт

Обучая компьютер пользоваться естественными языками, компьютерные лингвисты и программисты устраивают эксперименты. Например, предлагают машине самостоятельно создавать художественные произведения.
-
Новый «Гарри Поттер»
В 2017 году компания Robotics Botnik загрузила в память компьютера восемь томов истории Дж. К. Роулинг о Гарри Поттере. Обработав полученный текст, компьютер написал собственный рассказ, который назвал «Гарри Поттер и Портрет Того, что Выглядело как Большая Кучка Пепла». Люди писали в программе первое слово, а дальше запускался алгоритм, построенный на цепях Маркова – аналогичным образом смартфон предлагает нам продолжение сообщений или автозамену. Алгоритм сохранял стилистику Роулинг и пользовался словами, содержащимися в книгах. Вот фрагмент того, что получилось:
«Малфой!» — сказала Гермиона.
Гарри наблюдал за ним. Он был похож на Мадам Максим. Когда она зашагала вверх по неправильной лестнице, чтобы посетить самого себя».
-
Автопоэт
Проект Яндекса «Автопоэт» активно развивается с 2006 года. В его основе – алгоритм, который автоматически определяет стихотворный размер заданной фразы. Автопоэт рифмует пользовательские запросы, составляя из них стихотворения разных объемов и форм. Вот, например, его четверостишие с размышлением о собственном «Я»:
«дон камизи перевод
что такое промокод
как потеет бегемот
почему я идиот»
Или хокку – тоже его авторства:
«сценарий свадьбы
пенза торговые центры
обида в загсе»
-
Рецепты от робота
Большое количество проектов построены на том, что нейросеть обрабатывает обределенный массив данных и пытается создать что-то новое, основываясь на них. Например, проект «Нейрокухня» генерирует собственные кулинарные рецепты. Но мы не уверены, что кто-то готов это пробовать. К примеру:
«Газированный баклажан, творог 1-22-22, 6-12 шт. Сочно, почки одинаковой величины. Букет нашинкованных морковь, 3 шт. картофеля нарезать тряпкой. Смешать половину блинчиков
и закрыть, затем семена огурца нарезать. Плов бланшировать в соленой воде и подать на стол».
-
Альтернативная литература
Еще один интересный проект создал Борис Орехов. С помощью векторных моделей его алгоритм обработал произведения русских классиков и заменил в них каждое слово на синоним.
Вот как выглядит переработанное четверостишие из «Евгения Онегина» А.С. Пушкина:
«Поговорить об Ювенале,
В середине записки оставить vale,
Да вспомнил, хоть не без прегрешения,
Из Энеиды два стихотворения»
Для сравнения – оригинал:
«Потолковать об Ювенале,
В конце письма поставить vale,
Да помнил, хоть не без греха,
Из Энеиды два стиха».
А так алгоритм начал роман «Мастер и Маргарита» М.А. Булгагова:
«Случайно весною, в полдень невиданно жаркого восхода, в Казани, на Митрополичьих ручьях, появились два согражданина».
Оригинал: «Однажды весною, в час небывало жаркого заката, в Москве, на Патриарших прудах, появились два гражданина».
Перспективы
Если сравнивать качество машинного перевода, работу поисковиков или способности голосовых ассистентов в десять лет назад и сейчас, то можно невооруженным глазом, даже без аналитики отметить резко возросшее качество.
По мнению Бориса Орехова, сейчас в том, что связано с компьютерной лингвистикой и обучением компьютера языкам, длится период подъема и оптимизма. Есть инструменты, которые можно улучшать дальше, есть направления, в которых можно работать, и проблемы, требующие решения.
Кстати, оценить, насколько владеет языком и понимает вас голосовой ассистент, можно поиграть с Алисой от «Яндекса» в «Угадай героя» или «Закончи пословицу».