Системы на основе ИИ постоянно учатся играть в простейшие видеоигры. Разработчики оценивают их успехи и таким образом проверяют эффективность и возможности нейросети. DeepMind — один из филиалов компании Google — создали новую систему под названием Agent57. Этот искусственный интеллект может побить средний результат человека в 57 играх приставки Atari 2600.
Обучение новой системы проходило в среде Arcade Learning — она обладает коллекцией классических игр, которые исследователи используют для проверки пределов своих моделей глубокого обучения. Ранее DeepMind использовал ту же технологию, чтобы побить профессиональных игроков в китайской настольной игре Go и видеоигре Starcraft II.
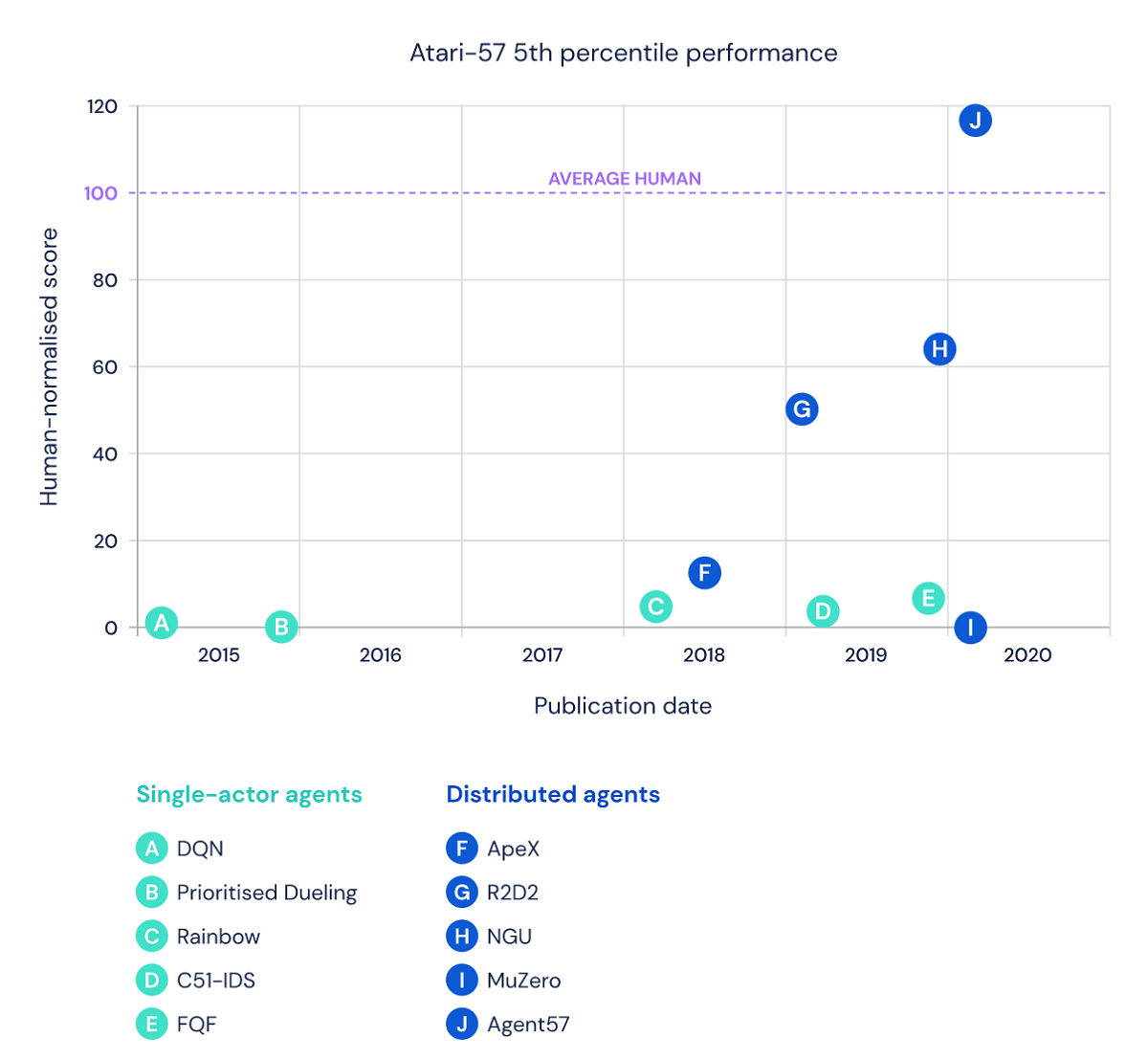
Разработанный командой DeepMind Agent57 использует тот же самый алгоритм глубокого обучения для достижения сверхчеловеческих уровней игры. Она сделала огромный скачок по сравнению с предыдущими версиями подобных систем и стала первым искусственным интеллектом, который превосходит базовые показатели человека. В частности, Agent57 доказал свои сверхчеловеческие навыки в Pitfall, Montezuma’s Revenge, Solaris и Skiing — играх, которые были серьезными проблемами для других ИИ.
Возможность изучить 57 различных задач через игровой процесс делает Agent57 более универсальной нейросетью.
Видеоигры обучают ИИ
Последняя разработка команды из Google добилась этого умения, оперируя методами глубокого обучения с подкреплением, технику машинного обучения, которая помогает ИИ совершенствовать свои конечные решения, пробуя разные подходы и учась на своих же неудачах. Игры в свою очередь — отличный способ проверить подобные системы. Они ставят различные задачи, которые вынуждают ИИ предлагать и использовать различные стратегии, и в то же время они имеют четкий критерий успеха — игровые баллы — для обучения.
Но четыре игры Atari оказались непростыми и некоторые системы годами боролись с ними. В Montezuma’s Revenge и Pitfall ИИ должен испробовать множество различных стратегий, прежде чем он найдет самую работающую. А в Solaris и Skiing между действием и вознаграждением могут быть долгие ожидания. Чтобы раскрыть результаты того или иного решения, требуется время, что усложняет задачу ИИ. Системы в течение довольно длительного времени пытаются понять, какие ходы приносят наибольшую отдачу.
Как им удалось побить самые сложные игры
Agent57 играет в Montezuma’s Revenge
Для решения этих задач Agent57 объединяет многочисленные улучшения, которые внесла команда DeepMind. В качестве основы они использовали сеть Deep-Q, ИИ, который впервые в 2012 году побил несколько игр Atari. Новая версия системы обладает особой формой памяти, которая позволяет ей принимать решения на основе того, что она уже ранее видела в игре. Также разработчики внедрили новую систему вознаграждений, которые побуждают ИИ более полно исследовать свои возможности, прежде чем выбирать стратегию.
Этими различными методами затем управляет один компьютер-смотритель, который уравновешивает компромиссы между дальнейшей разработкой конкретной стратегии и проведением дополнительных испытаний.
Таким образом разные компьютеры изучают отдельные аспекты игр. Затем их собранные результаты передаются главному устройству, которое анализирует их все для выработки наилучшей стратегии.
Agent57 играет в Pac-Man
В результате получается универсальная система, которая может справиться с целым рядом различных задач — а это ключевой показатель возможностей ИИ. Большинство систем склонны быть хорошими в одном деле. Обучение искусственного интеллекта для выполнения нескольких сложных задач — один из главных вопросов в области глубокого обучения.
Тем не менее DeepMind признает, что Agent57 еще можно улучшить. Хотя эти результаты впечатляют, ИИ может выучить одну игру за раз, что пока не полностью соответствует умениям людей. Уроки, извлеченные из Agent57, могут помочь повысить производительность, даже если навыки человеческого уровня пока не достижимы.