
Провайдер FirstVDS запустил тарифы с виртуальными GPU (vGPU) на базе NVIDIA L40S. Теперь в линейке два варианта: можно арендовать физическую видеокарту целиком (доступно с ноября 2025 года) или получить гарантированную долю виртуальной видеокарты.Компания также сравнила обе технологии в тестах и опубликовала результаты: скорость инференса LLM, генерацию видео и потребление видеопамяти.

{kind=link}
Теперь на сайте провайдера доступны четыре тарифа vGPU — от 4 до 16 ГБ видеопамяти. Технология vGPU делит физическую видеокарту на несколько профилей с фиксированной долей ресурсов. Серверы работают на виртуализации KVM с процессорами AMD EPYC. Стоимость — от 299 рублей в сутки.
Для сравнения, тарифы с физическим GPU (Passthrough) стартуют от 1150 ₽/сутки. В них доступны RTX 4090 и 5090, L4 и L40S — вся видеокарта полностью закрепляется за одной виртуальной машиной.
За последние полгода спрос на GPU-серверы вырос кратно — в первую очередь из-за задач, связанных с LLM, генерацией изображений и видео. Но не каждому проекту нужна 100% мощность физической карты. Разработчики, Data Science-команды и небольшие студии часто ищут более доступный вход с предсказуемой долей ресурсов. vGPU как раз закрывает этот запрос.
«В ноябре мы закрыли потребность в сырой мощности, запустив GPU Passthrough. Но рынку нужен не только потолок производительности, но и адекватная юнит-экономика. vGPU закрывает именно этот сегмент — снижает порог входа до 300 рублей в сутки. Мы прогнали бенчмарки. Сравнивать виртуалку с выделенной картой в лоб бессмысленно — физика берет свое, чудес не бывает. Наша цель была другой: четко очертить границы применимости. Показать механику, при которой vGPU вытягивает нагрузку, и где проходит черта, за которой пора брать полноценное железо».
Никита Попов, директор по продукту FirstVDS
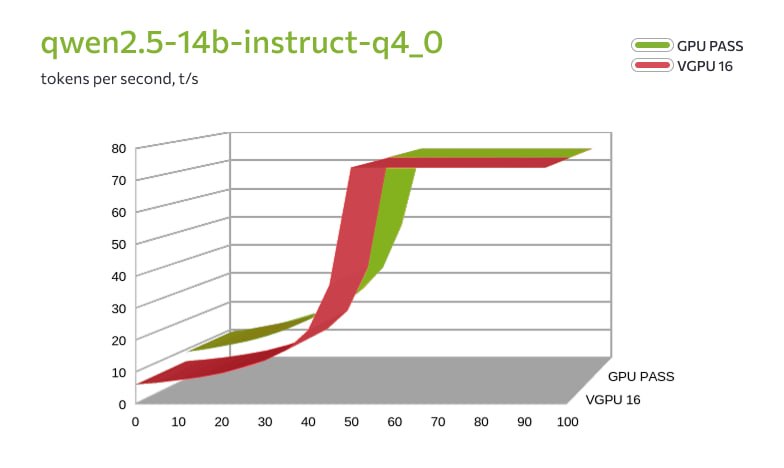
Также компания протестировала две конфигурации: GPU Passthrough (L40S, 48 ГБ, 16 ядер CPU) и vGPU 16 ГБ (8 ядер CPU). В сценариях использовались инференс LLM через llama.cpp (модели Qwen 2.5 и 3.6) и генерация видео через ComfyUI с шаблоном Wan2.2 TI2V 5B Hybrid.Физическая карта ожидаемо обгоняет виртуальные GPU по производительности. Но обнаружилось два важных нюанса.
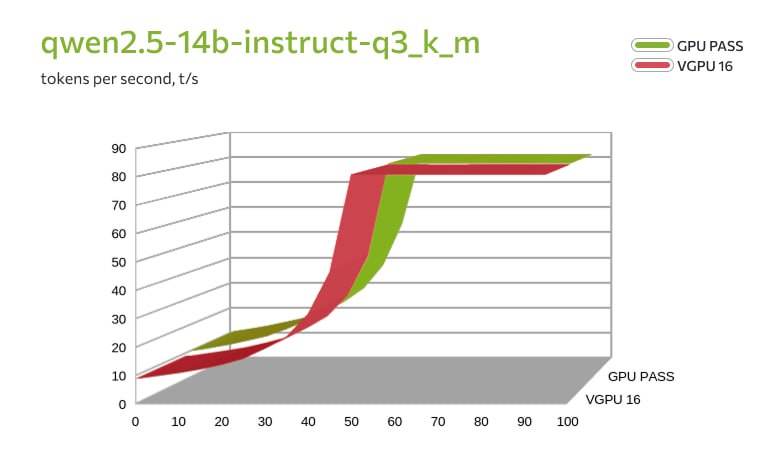
Во-первых, при тестировании моделей среднего размера (qwen2.5-14b в двух вариантах квантизации — q3_k_m и q4_0) на vGPU-16 и Passthrough оказалось, что при полной загрузке модели в видеопамять скорость генерации токенов практически не отличается. Разница возникает только в смешанном режиме CPU+GPU (до 30–40 слоев), где vGPU-16 сдерживает вдвое меньшее количество ядер процессора.
Во-вторых, более крупные модели (Qwen3.6-35B) в vGPU-16 полностью не загружаются — памяти не хватает, они работают только в смешанном режиме CPU+GPU со снижением скорости.
Генерация видео (ComfyUI) на vGPU-16 тоже работает, но с оговорками. Пришлось отключать часть функций и добавлять swap — иначе приложение аварийно завершалось. Время генерации на vGPU-16 ожидаемо выше, чем на Passthrough (для 5-секундного ролика — 293 секунды против 144).
Таким образом, несмотря на общее преимущество физической карты, виртуальный GPU способен решать определенные задачи — например, инференс средних языковых моделей при полной загрузке в видеопамять. Это делает vGPU осмысленным выбором, когда важнее доступная цена. Для более тяжелых сценариев (крупные модели, комфортная генерация видео без доработок) производительности vGPU может не хватить.